")
Antes de comenzar, quiero dejar claro que no soy médico ni pretendo serlo. Soy Ingeniero Electromecánico y me apasiona el mundo del Machine Learning y la Ciencia de Datos. En este post, compartiré mi experiencia trabajando con el Mammographic Mass Data Set y cómo los algoritmos de Machine Learning pueden ser utilizados en la detección temprana del cáncer de mama.
Mi objetivo es demostrar el potencial de la tecnología en la industria médica y cómo, trabajando juntos, los expertos en medicina y los expertos en tecnología pueden crear soluciones innovadoras para mejorar la salud y el bienestar de la sociedad.
Este post forma parte de una serie de publicaciones que he hecho en este blog en los últimos meses sobre Machine Learning. Los invito a darse una vuelta por nuestra sección dedicada a este apasionante tema. Sin más que decir, comencemos con este post.
Mammographic Mass Data Set
Cuando se trabaja en Machine Learning, los datasets son una parte fundamental del proceso de aprendizaje. Son conjuntos de datos ordenados que se utilizan para desarrollar y modelas algoritmos de Machine Learning.
Existe toda clase de datasets disponibles en línea que abarcan desde la clasificación de imágenes, audio, videos y datos de usuario, hasta conjuntos de datos médicos como el que veremos en este post, el Mammographic Mass Data Set. Este dataset es particularmente importante para la detección temprana del cáncer de mama, ya que contiene más de 800 casos de masas mamarias benignas y malignas.
El Mammographic Mass Data Set es, en sí, un archivo en formato CSV que se puede visualizar y editar en Excel:
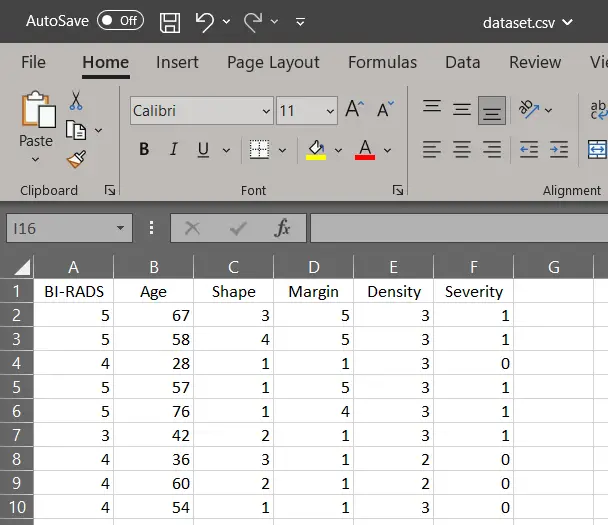
Este dataset cuenta con 830 registros de los resultados de mamografías en las que se encontraron masas. El dataset contiene datos de edad, forma de la masa, características del margen de la masa, densidad y el índice BI-RADS. La columna «severity» indica el resultado de una posterior biopsia, en la que se logró identificar si la masa detectada es un tumor maligno o no.
Los números en cada una de las filas del dataset representan lo siguiente:
-
- Evaluación BI-RADS: una clasificación de la Sociedad Radiológica de América del Norte (American College of Radiology) para la evaluación de la calidad de las mamografías, que va del 1 al 5 (ordinal, no predictivo).
- Edad (age): edad de la paciente en años.
- Forma de la masa mamaria (shape): redonda=1, ovalada=2, lobulada=3, irregular=4 (nominal).
- Margen de la masa mamaria (margin): circunscrito=1, microlobulado=2, oscurecido=3, mal definido=4, espiculado=5 (nominal).
- Densidad de la masa mamaria (density): alta=1, iso=2, baja=3, con contenido graso=4 (ordinal).
- Severidad (severity): una etiqueta que indica si la masa mamaria es benigna (0) o maligna (1).
Estos datos pueden ser descargados en su formato original en sitios web como Kaggle. El dataset contiene datos de masas benignas y malignas que se han identificado en mamografías digitales de campo completo recopiladas en el Instituto de Radiología de la Universidad Erlangen-Núremberg entre 2003 y 2006.
¿Qué tipo de análisis haremos?
BI-RADS es la sigla de «Breast Imaging Reporting and Data System», un sistema de informes y recopilación de datos de imágenes mamográficas desarrollado por la Sociedad Radiológica de América del Norte (American College of Radiology).
El sistema BI-RADS está diseñado para proporcionar un marco estandarizado para informar sobre hallazgos mamográficos y evaluar la necesidad de una biopsia de mama. El sistema utiliza una escala de clasificación numérica del 0 al 6 para calificar las mamografías, donde 0 indica que se necesita más información y 6 indica que ya se ha diagnosticado cáncer de mama.
El sistema BI-RADS también incluye descripciones detalladas de las características de las lesiones mamarias que se observan en las imágenes mamográficas, como la forma, el tamaño, el margen y la densidad, entre otras.
Aunque la mamografía es el método más efectivo para la detección temprana del cáncer de mama disponible en la actualidad, el bajo valor predictivo positivo de la biopsia de mama como resultado de la interpretación de los resultados de la mamografía conduce a aproximadamente el 70% de biopsias innecesarias con resultados benignos. Esto significa que detectar una masa en una mamografía no siempre indica la presencia de cáncer, y en 7 de cada 10 ocasiones la biopsia es innecesaria.
Para abordar este problema, en los últimos años se han propuesto varios sistemas de diagnóstico asistido por computadora (CAD). Estos sistemas ayudan a los médicos en su decisión de realizar una biopsia de mama en una lesión sospechosa detectada en una mamografía o de realizar un seguimiento a corto plazo en su lugar. Al mejorar la precisión de la detección del cáncer de mama, los sistemas CAD tienen el potencial de reducir la necesidad de biopsias innecesarias y mejorar la calidad de vida de los pacientes, a la vez que se reducen los costos asociados con la atención médica
En este post, nuestro objetivo es explorar la relación entre los atributos del conjunto de datos Mammographic Mass Data Set, incluyendo la evaluación BI-RADS, la edad del paciente, la forma, la densidad y el margen, y utilizarlos para predecir si el resultado de la biopsia confirmará un tumor maligno o no.
Para ello seleccionaremos una cantidad de muestras (80%, unos 664 registros) y las usaremos para entrenar un algoritmo de inteligencia artificial. Por ejemplo:
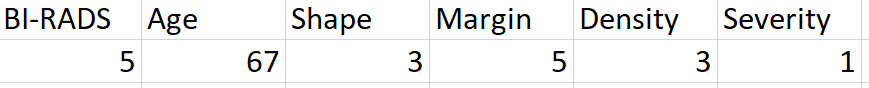
Este registro nos indica que en una mamografía a una señora de 67 años se obtuvo una evaluación BI-RADS de 5, con una masa de forma lobulada (3), margen espiculado (5) y densidad baja (3). Cuando se hizo la biopsia se identificó que el tumor era maligno.
Básicamente le diremos a un programa en la computadora las combinaciones que llevan a un determinado diagnóstico. Ese programa «aprenderá» con cada una de los 664 registros que le mostraremos. Luego, con lo aprendido, el modelo tratará de predecir el valor de la columna «severity» con el 20% de los datos restantes (166 registros). Es decir, recibiremos 166 datos de mamografías y para cada una trataremos de predecir el resultado de la biopsia, sin necesidad de hacer la biopsia.
Como estamos trabajando con datos ya conocidos, cuando hagamos una predicción podremos evaluar si acertamos o no. Cuantificaremos los aciertos y las equivocaciones y definiremos un porcentaje de eficiencia del proceso de clasificación.
Desde ya les adelanto que el mejor resultado que pude obtener fue 84%. Es decir, de los 166 registros de mamografías en los que probé el modelo de Machine Learning logró predecir el resultado de la biopsia en 140. Hubo 26 equivocaciones, lo cual es mucho cuando se trata de la vida de personas. Sobre estos resultados y su importancia hablaremos más adelante.
Construyendo un algoritmo de Machine Learning
Lo primero que hice con este dataset fue probar los modelos básicos conocidos de Machine Learning, específicamente el clasificador Random Forest. Utilicé el siguiente código:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score def loadDataset(fileName): data = pd.read_csv(fileName) y = np.array(data.iloc[:, 5]) x = np.array(data.iloc[:, :5]) return x, y dataset_x, dataset_y = loadDataset("../../../../datasets/mammographic_mass/dataset.csv") train_x, test_x, train_y, test_y = train_test_split(dataset_x, dataset_y, test_size=0.2, random_state=42) # Define the model model = RandomForestClassifier() # Train the model model.fit(train_x, train_y) # Make predictions on the test data pred_y = model.predict(test_x) # Evaluate the model accuracy = accuracy_score(test_y, pred_y) print('\nTest accuracy:', accuracy) |
Sí, así luce un código de Machine Learning. Parece complicado, pero es un modelo relativamente sencillo. Este código lo pueden descargar de nuestro repositorio de Github.
El resultado de la ejecución de este algoritmo produjo una eficiencia del 78.91%. Pensé que con Random Forest obtendría un mejor resultado, pero no fue así. Intenté optimizar los hiperparámetros con este código y logré mejorar la eficiencia a 82.5%.

Sí hubo una mejora, pero no me siento cómodo con la utilización de 500 estimadores. Definitivamente este no es el mejor ejemplo de uso de un clasificador Random Forest.
En este punto decidí probar otros algoritmos clásicos de Machine Learning. Construí un algoritmo que prueba todos los modelos disponibles en Sklearn y me devuelve el modelo que presentó el mejor resultado. Este es el código:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.utils import all_estimators # Define a function to load the dataset def loadDataset(fileName): data = pd.read_csv(fileName) y = np.array(data.iloc[:, 5]) x = np.array(data.iloc[:, :5]) return x, y # Load the dataset dataset_x, dataset_y = loadDataset("../../../../datasets/mammographic_mass/dataset.csv") # Split the dataset into training and testing sets train_x, test_x, train_y, test_y = train_test_split(dataset_x, dataset_y, test_size=0.2, random_state=42) # Get a list of all classification models in scikit-learn estimators = all_estimators(type_filter='classifier') # Define variables to store the best model and its accuracy best_model = None best_accuracy = -1 # Loop over all classification models for name, ClassifierClass in estimators: try: # Create an instance of the model model = ClassifierClass() # Train the model model.fit(train_x, train_y) # Make predictions on the test data pred_y = model.predict(test_x) # Evaluate the model accuracy = accuracy_score(test_y, pred_y) # Update the best model and its accuracy if accuracy > best_accuracy: best_model = model best_accuracy = accuracy print('Model: {}, Accuracy: {}'.format(name, accuracy)) except Exception as e: # Some models may raise exceptions, so we catch them and print an error message print('Error with model {}: {}'.format(name, e)) # Print the best model and its accuracy print('\nBest model: {}, Accuracy: {}'.format(type(best_model).__name__, best_accuracy)) |
Este código está disponible en Github. En total se probaron 38 modelos distintos de clasificación, todo el repertorio disponible en Sklearn. El modelo con el mejor performance de todos fue LogisticRegression, con un 84.33% de eficiencia en la clasificación.
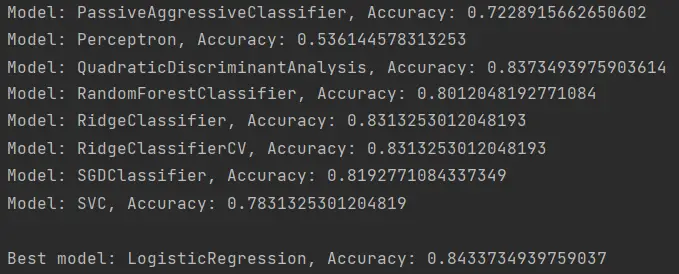
Como ya mencionamos antes, nuestro modelo ha logrado clasificar correctamente 140 de las 166 muestras del conjunto de datos Mammographic Mass Data Set. Luego de algunos ajustes finales logré subir hasta 85.5%, lo cual me da 142 resultados válidos.
Si bien esto es un resultado prometedor, aún hay margen para mejorar su eficacia. Para lograrlo, podríamos aplicar diferentes técnicas, como realizar una selección de características más precisa para determinar qué atributos son los más relevantes para la clasificación o realizar un proceso más exhaustivo de limpieza y preprocesamiento de los datos.
Tambien podríamos utilizar técnicas de aprendizaje profundo, como redes neuronales o modelos de deep learning, para mejorar la precisión de nuestro modelo de clasificación, pero creo que no tendría caso. ¿Utilizar Deep Learning para un modelo de solo 5 features? Me parece excesivo.
La verdad no estoy muy convencido de que sea posible mejorar la eficiencia de este proceso de clasificación más allá de un 2 o 3%. Las razones por las que creo esto las explicaré a continuación.
Posibles fuentes de error en el dataset
En mi opinión, el conjunto de datos Mammographic Mass Data Set es una excelente herramienta para demostrar el potencial de Machine Learning en el diagnóstico médico. Sin embargo, debemos tener en cuenta que el conjunto de datos en sí es bastante simple. Solo contamos con cinco características para entrenar nuestro modelo, lo que limita nuestra capacidad para capturar la complejidad del cáncer de mama.
Es importante recordar que la detección temprana del cáncer de mama es un proceso complejo que involucra múltiples factores, más allá de los resultados de una mamografía. La mamografía es una herramienta importante, pero por sí sola no es suficiente para hacer un diagnóstico completo de cáncer. En muchos casos, se requiere una biopsia para confirmar la presencia de células cancerosas.
Creo que si quisiéramos mejorar la eficiencia de este algoritmo de clasificación, se necesitaría considerar factores como:
-
- Aumentar el volumen de datos de entrenamiento.
- Agregar más características al modelo. Esto podría incluir factores de riesgo, como el saber si la persona fuma o no, consumo de alcohol, el historial familiar de cáncer, si la persona ya ha padecido cáncer, su peso, su profesión, entre otros.
- Tamaño de la lesión mamaria en milímetros.
- Número de lesiones mamarias presentes en la mamografía.
- Grado de asimetría mamaria, que mide la diferencia de densidad entre las mamas izquierda y derecha.
- Densidad mamaria total, que es una medida de la cantidad de tejido mamario fibroglandular en relación con el tejido adiposo.
- Volumen de la lesión mamaria, que podría calcularse a partir del tamaño de la lesión y su forma.
- El valor de los biomarcadores, como los niveles de estrógeno y progesterona, que pueden proporcionar información adicional sobre el riesgo de cáncer de mama.
Yo la verdad no estoy capacitado para hablar de este tema, pero tengo una idea general de qué factores de riesgo se pueden incluir en este dataset.
Entre más datos le proporcionemos al modelo, más eficiente será. Sin embargo, no se trata de agregar datos por agregar. Hace falta ver qué tan correlacionados están estos datos con el diagnóstico final.
En el caso del dataset actual, con Machine Learning podemos calcular la correlación de los datos y determinar cuales son los factores más importantes en este proceso de clasificación. Utilizando este código disponible en nuestro repositorio logré obtener los siguientes resultados:
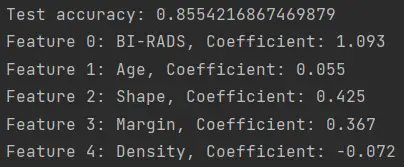
Lo que esto nos indica es que la importancia de cada uno de los datos con los que alimentamos el modelo. En este caso, el coeficiente más grande corresponde a la característica «BI-RADS», lo que sugiere que esta característica es la más importante para predecir la malignidad del tumor. Las características «Shape» y «Margin» también tienen coeficientes importantes, lo que indica que estas características también son relevantes para la predicción.
La edad de la persona tiene un impacto positivo en la predicción, aunque much menor que las otras características. La característica «Density» tiene un impacto negativo en la predicción, lo que sugiere que un valor alto de densidad se asocia con una probabilidad más baja de que el tumor sea maligno.
De esta forma podemos concuir que para este dataset lo más importante es el índice BI-RADS. Y esa puede ser precisamente otra de las razones por la cual nuestro modelo no logra una mejor precisión en el proceso de clasificación.
BI-RADS no es perfecto. Existen desventajas:
-
-
Subjetividad: El sistema BI-RADS se basa en la interpretación subjetiva de las imágenes mamográficas por parte del radiólogo, lo que puede dar lugar a variaciones en la interpretación de diferentes radiólogos y, por lo tanto, a resultados inconsistentes.
-
Limitaciones en la detección de cáncer: Aunque el sistema BI-RADS puede ser útil para detectar ciertos tipos de cáncer de mama, puede tener limitaciones en la detección de otros tipos, como el cáncer de mama inflamatorio o el cáncer de mama lobular, que pueden tener características distintas a las que se evalúan en el sistema BI-RADS.
-
No es un diagnóstico definitivo: El sistema BI-RADS es una herramienta de evaluación de riesgos y no es un diagnóstico definitivo de cáncer de mama. Los resultados de la evaluación del riesgo BI-RADS deben ser utilizados junto con otros factores de riesgo y pruebas de diagnóstico adicionales para determinar si se requiere una biopsia u otro tratamiento.
-
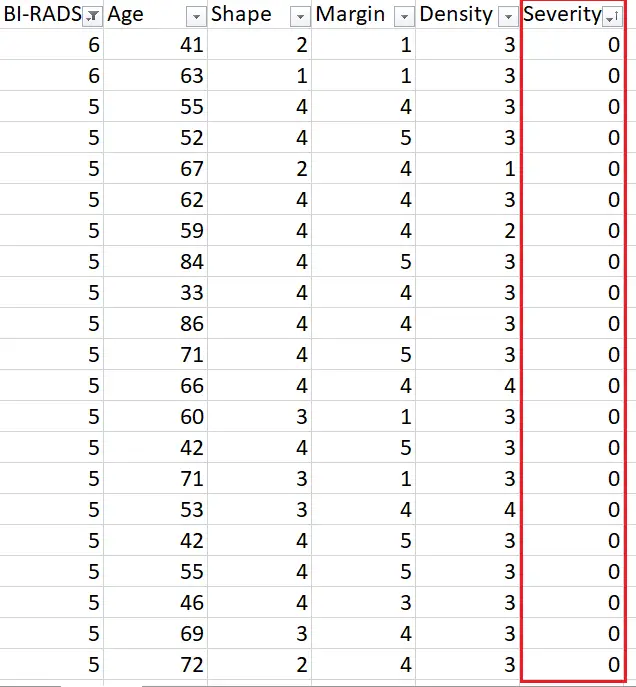
Un ejemplo de esto lo podemos apreciar en el propio dataset. Si utilizamos Excel para filtrar los datos en función de BI-RADS veremos lo siguiente:
El Internet me dice esto sobre BI-RADS:
Las categorías BI-RADS son las siguientes:
- 0 – Incompleto
- 1 – Negativo
- 2 – Hallazgo benigno
- 3 – Probablemente benigno
- 4 – Anormalidad sospechosa
- 5 – Altamente sugestivo de malignidad
- 6 – Malignidad conocida demostrada por biopsia
Se espera que los resultados de un índice de BI-RADS 5 o 6 representen un diagnóstico positivo de cáncer de mama. Sin embargo, al examinar las imágenes, es evidente que hay varios casos de tumores benignos con un índice de BI-RADS de 5, incluyendo dos con un índice de BI-RADS de 6. Esto podría deberse a errores en el registro de los datos o a la subjetividad del radiólogo que interpretó las imágenes.
Sea como sea, el modelo de Machine Learning que entrenamos aquí depende mucho de ese índice y se podría ver negativamente influenciado por un índice mal asignado.
Tendencias en cuanto a detección de cáncer con Machine Learning
En realidad, en este post solo hemos hecho una exploración superficial sobre el potencial de Machine Learning en el diagnóstico médico. Las tendencias más recientes en este campo se centran en la identificación de patrones en imágenes médicas, incluyendo las mamografías.
En lugar de confiar únicamente en las características clínicas y los datos de los pacientes, los algoritmos de Machine Learning pueden analizar directamente la imagen resultante de la mamografía para detectar patrones y señalar posibles tumores. Esto podría mejorar significativamente la precisión y eficacia del diagnóstico del cáncer de mama.
Los algoritmos de Machine Learning tienen el potencial de procesar grandes cantidades de datos genéticos y de expresión génica relacionados con el cáncer de mama. Esta capacidad de análisis de datos puede ayudar a identificar pacientes con mayor riesgo de desarrollar cáncer de mama en el futuro. La identificación temprana del riesgo puede permitir una intervención médica más temprana y efectiva, mejorando así las posibilidades de supervivencia y recuperación del paciente.
Además, los algoritmos de Machine Learning pueden ser entrenados para identificar patrones específicos en los datos clínicos de los pacientes, como el historial médico y los factores de riesgo. Con estos patrones identificados, los algoritmos pueden predecir el riesgo de cáncer de mama con mayor precisión y ofrecer una atención médica personalizada y específica a las necesidades de cada paciente. Esto puede conducir a tratamientos más efectivos y reducir la necesidad de procedimientos médicos innecesarios.
Finalmente, los algoritmos de Machine Learning pueden ser utilizados para personalizar el tratamiento del cáncer de mama. La personalización del tratamiento puede mejorar los resultados de tratamiento y reducir los efectos secundarios al utilizar datos específicos del paciente para determinar el tratamiento adecuado. La combinación de datos de múltiples fuentes, como datos de imágenes médicas, datos genéticos y datos clínicos, puede proporcionar una visión más completa y precisa del riesgo y la progresión del cáncer de mama. En última instancia, esto puede mejorar la calidad de vida del paciente y ayudar a reducir los costos asociados con la atención médica.
Conclusiones
El uso de algoritmos de Machine Learning en la detección temprana del cáncer de mama es una herramienta prometedora en la industria médica. Si bien los resultados del modelo presentado en este post no son perfectos, muestran el potencial de la tecnología para ayudar a los expertos en medicina en la toma de decisiones más precisas y eficientes en la atención médica. El Mammographic Mass Data Set es, sin duda, un conjunto de datos muy interesante para dar los primeros pasos en este tema.
Es importante tener en cuenta que, aunque la mamografía es una herramienta valiosa, no es suficiente para hacer un diagnóstico completo de cáncer de mama y se deben considerar otros factores en el proceso de detección temprana. En general, este ejemplo demuestra la importancia del trabajo en equipo entre expertos en medicina y expertos en tecnología para crear soluciones innovadoras y mejorar la salud y el bienestar de la sociedad.
Muchas gracias por leer este post. Espero que haya sido útil y que hayas aprendido algo nuevo. Si tienes algún comentario, sugerencia o pregunta, no dudes en dejarlo en la sección de comentarios a continuación. Me encantaría saber tu opinión y continuar la conversación.















