
El HTTP o protocolo de transferencia de hipertexto es un protocolo de comunicación que permite el intercambio de información entre un cliente y un servidor web. Es, básicamente, el protocolo que permite a los usuarios del Internet en el mundo la visualización de páginas web.
El propósito de este post es explicar, de una manera muy sencilla, qué es y para qué se utiliza el HTTP. Para explicar esto utilizaremos ejemplos prácticos sencillos, con los cuales deben quedar claros los conceptos sobre este protocolo de comunicación. Vamos paso por paso.
¿Qué es un servidor web y qué es un cliente web?
Un servidor web o servidor HTTP es un software que permite el intercambio de información entre dos computadoras a través de Internet. Un ejemplo de este tipo de software es Apache, un programa que permite «crear» un servidor web en una computadora.
Hace un tiempo publiqué un post en este blog sobre como crear un servidor web local en Windows utilizando Apache. Básicamente con instalar Apache e iniciar el server, nuestra computadora se convierte en un servidor HTTP.
Un cliente web, por su parte, es un software que te permite hacer peticiones a un servidor web. Algunos ejemplos de clientes web son los navegadores tales como Google Chrome, Mozilla Firefox, Safari, Opera, Internet Explorer, Microsoft Edge, entre otros. Casi cualquier lenguaje de programación posee herramientas que permiten enviar peticiones HTTP a un servidor.
Vamos a ver un ejemplo sencillo de un servidor web y un cliente funcionando. Siguiendo los pasos explicados en el post sobre Apache, voy a iniciar el Apache server en mi computadora desde XAMPP. Al hacer esto se creará un servidor web cuya raíz se ubica en la carpeta C:\xampp\htdocs.
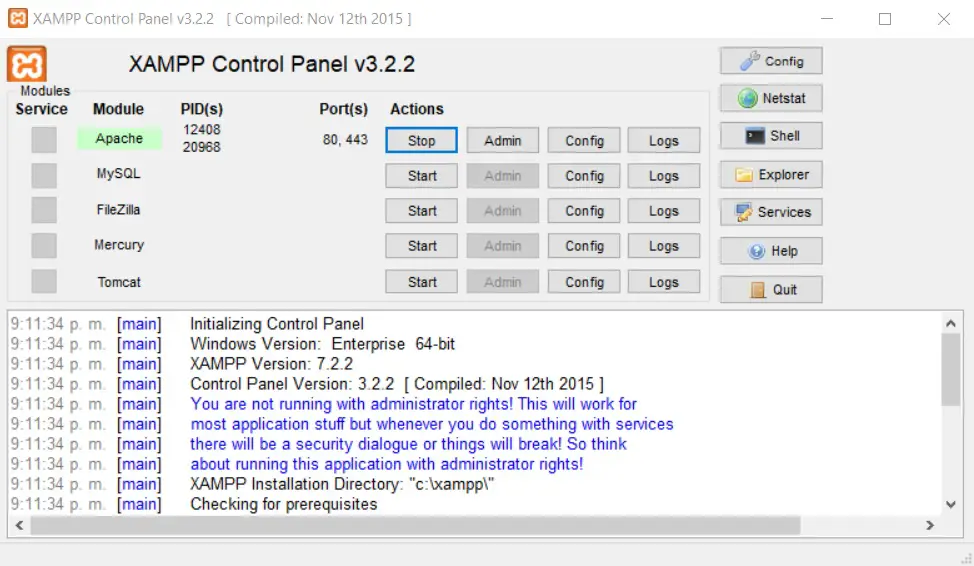 Por ahora en esa carpeta voy a colocar tres archivos de texto a modo de ejemplo. Así se debe ver el contenido de la carpeta C:\xampp\htdocs.
Por ahora en esa carpeta voy a colocar tres archivos de texto a modo de ejemplo. Así se debe ver el contenido de la carpeta C:\xampp\htdocs.

Nosotros sabemos que los 3 archivos están guardados en esa carpeta porque los vemos ahí a través del Explorador de Windows. Ahora trataremos de visualizar el contenido de esa misma carpeta, utilizando para ello un Cliente Web. Yo usaré Mozilla Firefox.
La dirección a través de la cual accedemos a nuestro servidor web local es http://localhost. Al escribir eso en Google Chrome, nos debe aparecer el siguiente resultado:
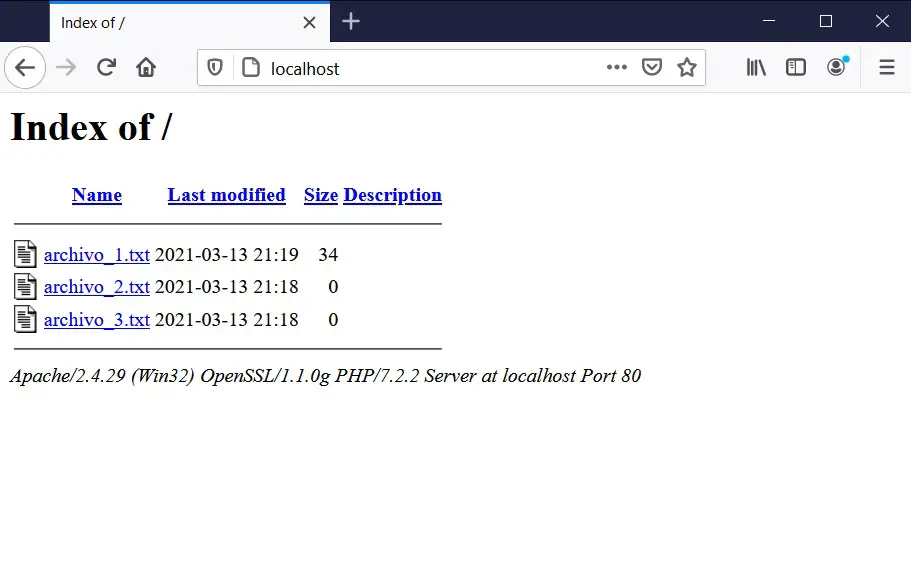
Como vemos en la imagen, el contenido de la carpeta C:\xampp\htdocs ha aparecido en nuestro navegador web. Y eso es lo que nos permite el servidor web (Apache), ver la información guardada en una carpeta de una computadora desde un navegador web (Firefox, en este caso). El mismo resultado se obtendría si se usa Chrome, Safari, Opera o cualquier otro navegador.
Localhost es el host a través del cual podemos acceder localmente al Apache Server. Este host puede cambiar para hacer referencia a archivos que están almacenados en otros servidores. Ese es el propósito de los dominios web (el nombre de las páginas web,el .com), el establecer un enlace entre clientes y servidores de manera remota, así mismo como el localhost nos permite establecer conexión entre un cliente web y un servidor web de manera local en nuestra computadora.
Volviendo al ejemplo, si hacemos clic en el nombre de alguno de los archivos, podemos ver el contenido del archivo de texto:
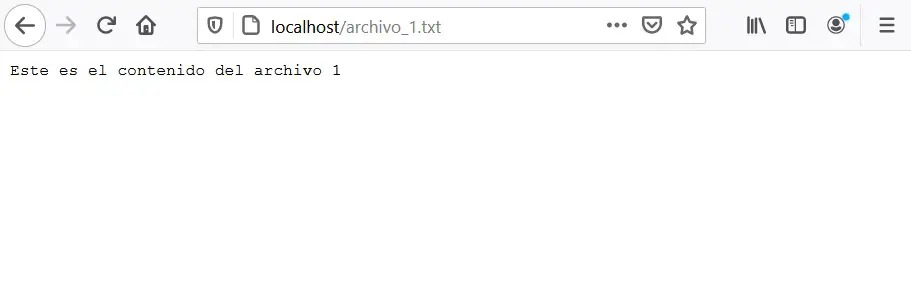 Los navegadores web también tienen la posibilidad de interpretar el texto guardado en los archivos en el servidor y convertirlo en elementos visuales. Para eso existe un lenguaje de programación que se llama HTML, el cual se utiliza específicamente para crear interfaces visuales interactivas a partir de texto plano. Veamos un ejemplo.
Los navegadores web también tienen la posibilidad de interpretar el texto guardado en los archivos en el servidor y convertirlo en elementos visuales. Para eso existe un lenguaje de programación que se llama HTML, el cual se utiliza específicamente para crear interfaces visuales interactivas a partir de texto plano. Veamos un ejemplo.
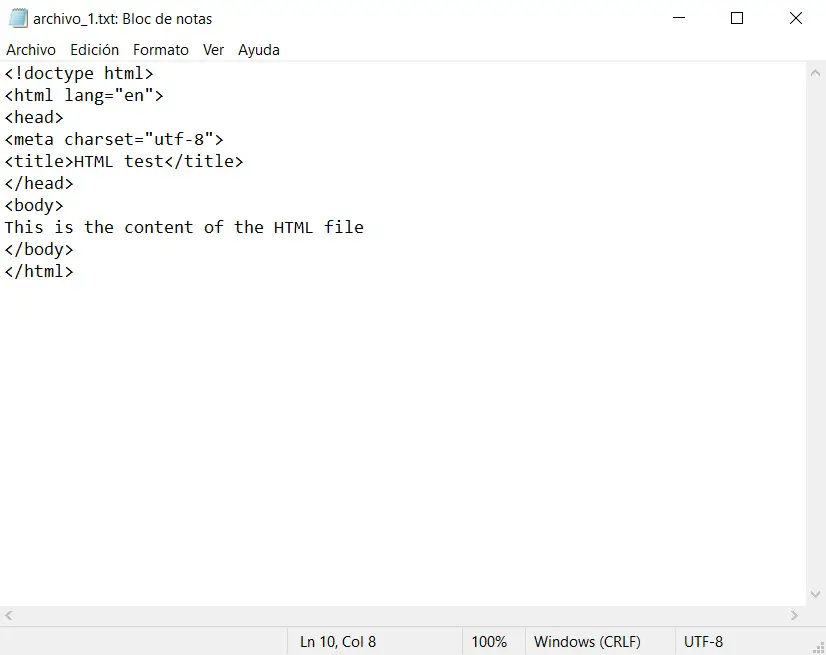
Dentro del archivo_1.txt colocaré el siguiente código:
|
1 2 3 4 5 6 7 8 9 10 |
<!doctype html> <html lang="en"> <head> <meta charset="utf-8"> <title>HTML test</title> </head> <body> This is the content of the HTML file </body> </html> |
Usando el Bloc de Notas, editamos el fichero.
 Cuando tratamos de visualizar este archivo en el navegador web veremos:
Cuando tratamos de visualizar este archivo en el navegador web veremos:
 El mismo contenido. ¿Por qué? Porque los archivos .txt no están hechos para ser renderizados por el navegador web. Así que si cambiamos el nombre del fichero a archivo_1.html veremos lo siguiente:
El mismo contenido. ¿Por qué? Porque los archivos .txt no están hechos para ser renderizados por el navegador web. Así que si cambiamos el nombre del fichero a archivo_1.html veremos lo siguiente:
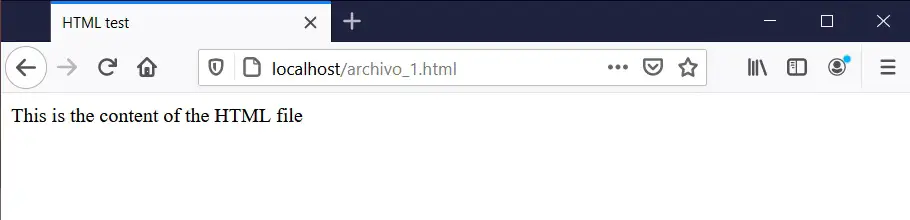 Aquí vemos como desaparece la mayor parte del código y simplemente se visualiza lo que aparece entre los tags <body> y </body>. Pero, en vez de texto plano podríamos hacer que aparezcan cosas interesantes como tablas, gráficos, imágenes, etc. Voy a modificar el archivo de texto y le pondré un código mucho más complejo:
Aquí vemos como desaparece la mayor parte del código y simplemente se visualiza lo que aparece entre los tags <body> y </body>. Pero, en vez de texto plano podríamos hacer que aparezcan cosas interesantes como tablas, gráficos, imágenes, etc. Voy a modificar el archivo de texto y le pondré un código mucho más complejo:
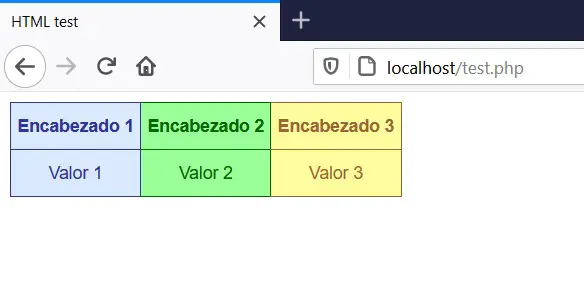
 Esta vez he incluido algunas líneas de CSS (hoja de estilos en cascada), con lo cual se pueden crear estilos visuales para el código en HTML. El código no lo escribí yo, sino que lo generé a través de un sitio web: HTML Tables generator. Cuando veo este código desde el navegador web tenemos:
Esta vez he incluido algunas líneas de CSS (hoja de estilos en cascada), con lo cual se pueden crear estilos visuales para el código en HTML. El código no lo escribí yo, sino que lo generé a través de un sitio web: HTML Tables generator. Cuando veo este código desde el navegador web tenemos:
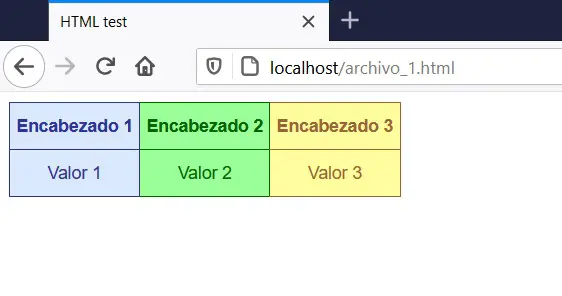 Lo que se muestra es una sencilla interfaz de una tabla de dos filas y 3 columnas, con distintos colores de letra y fondo en las celdas. De esta forma es como se construyen las páginas web, utilizando una combinación de HTML, CSS y lenguajes de programación del lado del servidor, como PHP, NodeJS, Python, Java, entre otros.
Lo que se muestra es una sencilla interfaz de una tabla de dos filas y 3 columnas, con distintos colores de letra y fondo en las celdas. De esta forma es como se construyen las páginas web, utilizando una combinación de HTML, CSS y lenguajes de programación del lado del servidor, como PHP, NodeJS, Python, Java, entre otros.
Este es el principio básico de las páginas web. Un sitio web no es más que una colección de archivos alojados en un servidor, a los cuales los usuarios acceden a través del protocolo de transferencia de hipertexto (HTTP). El HTTP lo único que hace es transmitir el texto almacenado en los archivos del servidor a los clientes web que envían peticiones al servidor. Los navegadores web son clientes web que tienen la capacidad de transformar los códigos en HTML y CSS (entre otras cosas) en elemento visuales, es decir, las páginas web a la que los usuarios acceden.
Puede que haya clientes web que no transformen el código en elementos visuales, sino que simplemente reciben el texto y te lo entregan tal como es. Por ejemplo, si uso un cliente web en Java y envío una petición a http://localhost/archivo_1.html, el resultado es el siguiente:
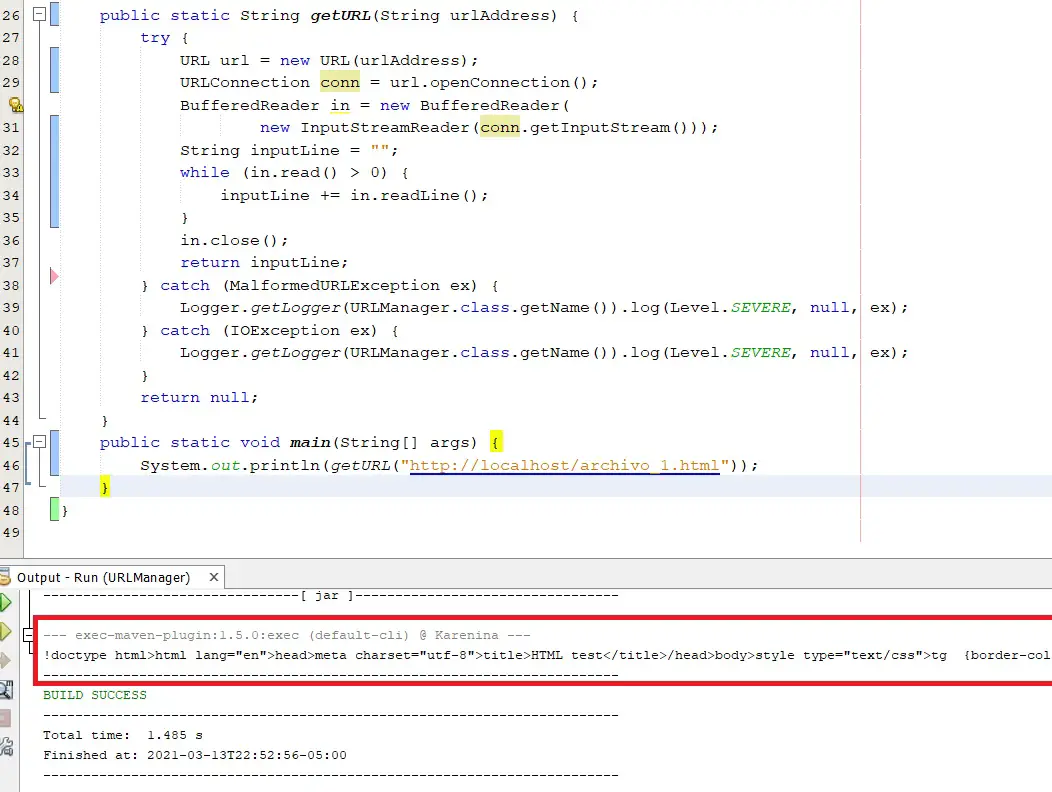 Como ya dije, casi cualquier lenguaje web permite configurar un cliente web que envía peticiones a un servidor y recibe texto de vuelta. No importa que no podamos verlo renderizado, ese texto nos sirve y podemos hacer muchas cosas con eso.
Como ya dije, casi cualquier lenguaje web permite configurar un cliente web que envía peticiones a un servidor y recibe texto de vuelta. No importa que no podamos verlo renderizado, ese texto nos sirve y podemos hacer muchas cosas con eso.
Lenguajes de programación del lado del servidor
Los lenguajes de programación del lado del servidor son lenguajes que se ejecutan en el servidor, donde los clientes no pueden ver lo que está sucediendo. Los lenguajes de programación del lado del cliente (como HTML y CSS) permiten que el cliente vea un resultado de manera visual, pero los del lado del servidor hacen cosas que los clientes no deben ver. Un ejemplo de estas cosas son las consultas a las bases de datos, donde normalmente se guarda información privada y completamente confidencial.
Un ejemplo de lenguaje web del lado del servidor es PHP. Es uno de los lenguajes más utilizados del mundo. Casi cualquier página web en Internet hoy día basa algún pedacito de su funcionamiento en PHP. Siendo un lenguaje sumamente fácil de utilizar, les mostraré un ejemplo de un script en PHP siendo ejecutado por un navegador web.
Crearé un archivo en mi servidor web al que llamará test.php, en el cual colocaré el siguiente código:
|
1 2 3 |
<?php echo("Hello world"); ?> |
Cuando accedemos a este archivo desde el navegador, veremos lo siguiente:
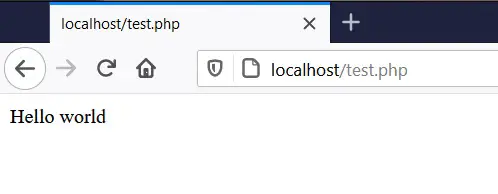 Básicamente eso es PHP. Son scripts que se guardan en archivos con extensión .php que al ser accedidos desde un cliente web, se ejecutan y hacen algo. Hoy en día muchas páginas están construidas en PHP, el cual tiene la capacidad de ser programado para generar HTML de manera dinámica. Por ejemplo, si nosotros queremos que al acceder al archivo test.php nos aparezca la tabla con los colores que hicimos en HTML, podemos decirle a PHP que abra el archivo HTML, extraiga el texto y se lo mande al navegador. Eso se puede lograr con el siguiente código:
Básicamente eso es PHP. Son scripts que se guardan en archivos con extensión .php que al ser accedidos desde un cliente web, se ejecutan y hacen algo. Hoy en día muchas páginas están construidas en PHP, el cual tiene la capacidad de ser programado para generar HTML de manera dinámica. Por ejemplo, si nosotros queremos que al acceder al archivo test.php nos aparezca la tabla con los colores que hicimos en HTML, podemos decirle a PHP que abra el archivo HTML, extraiga el texto y se lo mande al navegador. Eso se puede lograr con el siguiente código:
|
1 2 3 4 5 6 |
<?php $html = fopen("archivo_1.html", "r"); while ($line = fgets($html)) { echo($line); } ?> |
Con esto lo que hacemos es leer el archivo HTML e imprimir cada línea del archivo con la sentencia echo, la cual ya vimos que sirve para mandarle texto al cliente. El resultado de acceder a test.php con un navegador es:
 El mismo resultado que antes, visualmente. En la actualidad la mayor parte de las páginas web están construidas así, por pedazos. En unos archivos se guardan los estilos, en otro las distintas partes de la página, en otros los scripts para comportamiento dinámico y al final uno o varios archivos en PHP se encargan de hacer que los distintos pedazos de código encajen en una sola cadena de texto, la cual es enviada al navegador web. De esta forma podemos ver videos en Youtube, buscar cosas en Google o en Wikipedia, comprar cosas en Amazon, etc.
El mismo resultado que antes, visualmente. En la actualidad la mayor parte de las páginas web están construidas así, por pedazos. En unos archivos se guardan los estilos, en otro las distintas partes de la página, en otros los scripts para comportamiento dinámico y al final uno o varios archivos en PHP se encargan de hacer que los distintos pedazos de código encajen en una sola cadena de texto, la cual es enviada al navegador web. De esta forma podemos ver videos en Youtube, buscar cosas en Google o en Wikipedia, comprar cosas en Amazon, etc.
Y tampoco tiene que ser PHP quien se encarga de armar la página. En realidad puede ser cualquier otro lenguaje del lado del servidor. Hoy en día lo que sobran son opciones para trabajar en desarrollo web. En este post simplemente estoy tratando de compartir los conocimientos más básicos sobre este tema.
Los métodos de petición HTTP
Hasta ahora sabemos que el HTTP nos permite acceder a los archivos de texto que se encuentran almacenados en un servidor, incluyendo scripts de lenguajes que son ejecutados cuando hacemos peticiones desde un cliente web. Pero, hasta ahora solamente hemos hablado de recepción de información. Simplemente hemos enviado peticiones y recibido respuestas del servidor en la forma de hipertexto, el cual ya vimos que puede ser interpretado por un navegador web como elementos visuales.
En esta nueva sección vamos a tratar de comunicarnos a través de peticiones HTTP. Con esto quiero decir que vamos a intentar crear una comunicación bidireccional con el servidor, en la cual le enviaremos datos y recibiremos una respuesta que dependerá de los datos que enviemos.
Dentro del protocolo HTTP existen varios métodos de petición, los cuales mencionaremos a continuación:
- GET
- HEAD
- POST
- PUT
- DELETE
- TRACE
- OPTIONS
- CONNECT
- PATCH
- MOVE
- MKCOL
- PROPFIND
- PROPPATCH
- MERGE
- UPDATE
Yo personalmente no soy un experto en HTTP, pero creo que sí tengo los conocimientos mínimos requeridos para dirigirme a ustedes a través de este post. A partir de este punto me voy a enfocar en explicar los dos métodos de petición que más me interesan para este post: GET y POST. Estos son los métodos principales que se utilizan en las transacciones por HTTP, pero, como ya vimos, no son los únicos.
Al ser GET y POST los métodos más importantes para lo que quiero compartir en esta entrada, basaré el resto de este post en esos dos métodos y en usted quedará la responsabilidad de estudiar por su propia cuenta sobre los demás métodos, si así lo desea. Desde ya les digo que GET y POST son los más utilizados, aunque al no ser yo un experto en este tema podría estar equivocándome.
El método GET
El método GET es el más fácil de utilizar y comprender entre los que ya he mencionado. Es uno de los métodos más comunes y se utiliza para solicitar información desde una fuente específica dentro del servidor. Para poder entender el funcionamiento de GET, utilizaré un script en PHP con el cual quedará demostrado como es que funciona este método.
Con GET se puede enviar información al servidor a través de la propia URL utilizada en el envío de la petición. Por ejemplo, si accedemos a la siguiente URL:
http://localhost/test.php?param1=value1¶m2=value2
Con eso estaremos enviando dos parámetros y dos valores (value1 y value2). Esta información puede ser recibida y procesada en PHP. Un ejemplo de ello sería el siguiente script:
|
1 2 3 4 5 6 |
<?php $val1 = $_GET['param1']; $val2 = $_GET['param2']; $str = $val1.' '. $val2; echo($str); ?> |
Con ese pedacito de código podemos recibir dos valores a través de la URL e imprimir esos dos valores en el navegador web. Si guardamos ese código en el fichero test.php y lo probamos, veremos el siguiente resultado:
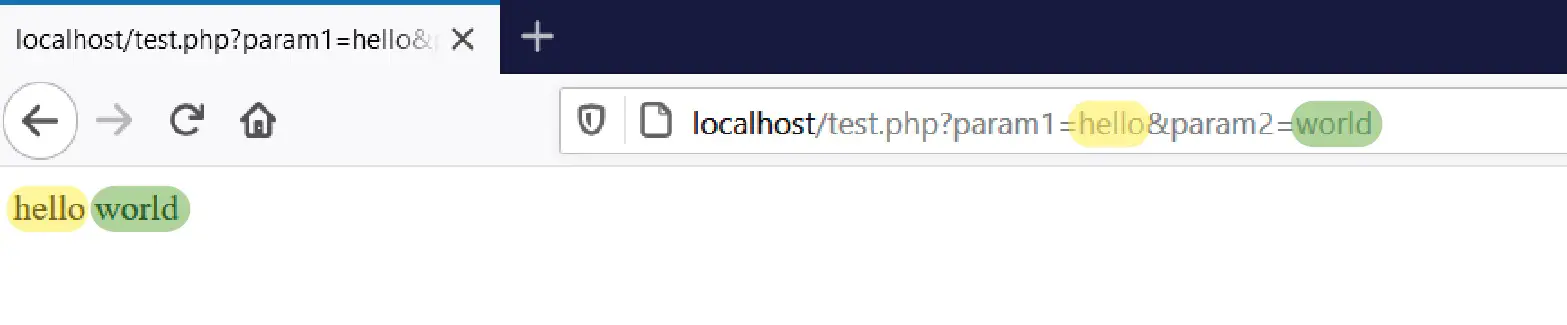 Vemos que los dos parámetros que enviamos en la URL aparecen impresos en el navegador. Si escribimos otra cosa, veremos que el resultado cambia conforme a la URL que usamos.
Vemos que los dos parámetros que enviamos en la URL aparecen impresos en el navegador. Si escribimos otra cosa, veremos que el resultado cambia conforme a la URL que usamos.
 También podemos hacer que al recibir los parámetros, PHP haga algo con ellos y te devuelva un resultado de salida. Por ejemplo, si usamos el siguiente código:
También podemos hacer que al recibir los parámetros, PHP haga algo con ellos y te devuelva un resultado de salida. Por ejemplo, si usamos el siguiente código:
|
1 2 3 4 5 6 |
<?php $val1 = $_GET['v1']; $val2 = $_GET['v2']; $res = $val1 * $val2; echo($res); ?> |
Usando esto habremos hecho una pequeña calculadora que toma dos valores, los multiplica y nos entrega el resultado. Al probar este script en nuestro navegador, veremos el siguiente resultado:

Fíjense que enviamos dos valores, el 5 y el 10 y en el navegador obtuvimos el producto de ellos, es decir, 50. Cambiamos los nombres de los parámetros de param1 y param2 a v1 y v2, demostrando que ahí podemos usar cualquier valor que queramos. También se podrían agregar otros parámetros/valores a la URL, de forma tal que a través del método GET se puede transferir una gran cantidad de valores al servidor.
Con este método es muy sencillo enviar información al server, pero también tiene sus limitaciones. Por ejemplo, la URL tiene un límite de tamaño de 2048 caracteres. También es un método muy inseguro, pues la información enviada como parámetro viaja en la forma de texto plano a través de la URL. Las URL usadas quedan almacenadas en el historial de búsqueda y en el caché del navegador web, por lo que la información enviada es fácilmente rastreable desde el navegador.
Si estamos haciendo una página web en la que se requiere que un usuario establezca un nombre de usuario y una contraseña, esta información jamás debe ser enviada utilizando el método GET. Cualquiera podría estar monitoreando nuestra navegación a través de la web y en la propia URL a las que accedemos sería muy sencillo extraer información sensitiva, si es que se utiliza el GET para enviarla.
El método POST
Si lo que queremos es enviar grandes volúmenes de información sin que esta pueda ser rastreada a través de la URL, sin contar con limitaciones de tamaño y utilizando un nivel de seguridad un poco mayor, para ello tenemos el método POST.
Con POST la información no se envía a través de la URL, sino que se empaca en el cuerpo de la petición. Cada petición en HTTP tiene un cuerpo en el cual se envían cierta información. Utilizando las herramientas adecuadas es posible agregar información al cuerpo de la petición para luego recibirla y procesarla en PHP.
El problema del POST es que no lo podemos construir tan sencillamente como una petición GET. El GET lo podemos probar directamente desde el navegador web, pero para construir un POST necesitamos hacerlo desde alguna herramienta o lenguaje de programación. Para ver el funcionamiento de este método, usaremos el siguiente script en PHP:
|
1 2 3 4 5 6 |
<?php foreach ($_POST as $key => $value) { echo $key .": ".$value; echo(" "); } ?> |
Este script, el cual guardaré en test.php, recibirá parámetros desde POST y los imprimirá en el cliente web. Para probar este script debemos hacerlo desde un lenguaje de programación. Yo usaré el siguiente script en Python:
|
1 2 3 4 |
import requests pload = {'param1':'hello','paparam2':'world'} r = requests.post('http://localhost/test.php',data = pload) print(r.text) |
Este script lo que hace es crear un JSON en el que hay dos parámetros (param1 y param2) y dos valores («hello» y «world»). Ese JSON se adjunta en una petición POST y luego se imprime el resultado devuelto por el script test.php.
Cuando ejecutamos el código en Python vemos el siguiente resultado:
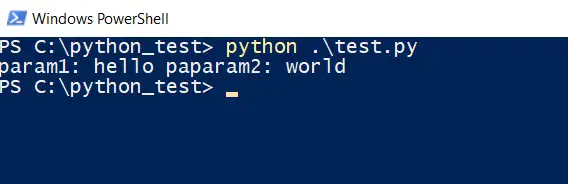 Ahora en vez de enviar esos dos parámetros voy a hacer que el script en PHP reciba cierta cantidad de números y te entregue la suma de las cantidades que recibe. El script en PHP sería el siguiente:
Ahora en vez de enviar esos dos parámetros voy a hacer que el script en PHP reciba cierta cantidad de números y te entregue la suma de las cantidades que recibe. El script en PHP sería el siguiente:
|
1 2 3 4 5 6 7 |
<?php $sum = 0; foreach ($_POST as $key => $value) { $sum = $sum + $value; } echo('El resultado es: '.$sum); ?> |
Desde Python le voy a enviar 4 valores: 10, 20, 30 y 40, cuya suma es 100. Veamos como sería el script en Python:
|
1 2 3 4 |
import requests pload = {'n1':10,'n2':20,'n3':30,'n4':40} r = requests.post('http://localhost/test.php',data = pload) print(r.text) |
El JSON en Python (almacenado en la variable pload) contiene los parámetros n1, n2, n3 y n4, con los valores 10, 20, 30 y 40 respectivamente. Esos valores se le pasan al script test.php a través de un POST y luego se imprime el resultado. Al ejecutar estos scripts, veremos esto:
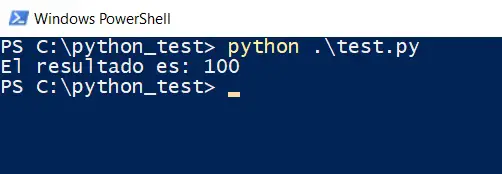 Como vemos, al ejecutar el script en Python obtenemos el resultado de la suma de los 4 números que le enviamos desde Python. En vez de esos 4 números podríamos enviar cualquier tipo de información codificada en JSON y al llegar a PHP podríamos hacer que la información sea almacenada en una base de datos o hacer otras muchas otras cosas interesantes.
Como vemos, al ejecutar el script en Python obtenemos el resultado de la suma de los 4 números que le enviamos desde Python. En vez de esos 4 números podríamos enviar cualquier tipo de información codificada en JSON y al llegar a PHP podríamos hacer que la información sea almacenada en una base de datos o hacer otras muchas otras cosas interesantes.
Conclusiones
Para entender qué es el protocolo de transferencia de hipertexto primero tuvimos que estudiar los conceptos de servidor web y cliente web. Dentro de estos conceptos vimos que a través de la transferencia de texto es como los usuarios de Internet pueden acceder a las páginas web. Los navegadores web son clientes web que se encargan de renderizar el texto recibido a través de HTTP y convertirlo en elementos visuales con los cuales las personas podemos interactuar.
También estudiamos un poco sobre lenguajes de programación del lado del servidor, principalmente PHP. Esto fue necesario para que pudiésemos estudiar algunos ejemplos de uso de los métodos GET y POST, dos de las principales funciones del protocolo HTTP.
Con el método GET se pueden enviar datos a través de la URL utilizada para hacer la petición HTTP. Este método es fácil de utilizar, pero no es seguro y tiene limitaciones en cuanto al volumen de información que se puede enviar.
El método POST es más seguro y carece de las limitaciones del método GET, pero es un poco más difícil de utilizar que GET. Mientras que para usar GET basta con tener un navegador web, para usar POST se requieren herramientas especiales o el uso de un lenguaje de programación. Afortunadamente casi cualquier lenguaje de programación tiene herramientas para enviar peticiones por HTTP, entre ellos Python.
Utilizando Python armamos algunas peticiones con POST y las enviamos a PHP, con lo cual pudimos comprobar que la transferencia de información entre cliente y servidor se cumple. Ahora lo que nos queda es asimilar el conocimiento que hemos adquirido en este post y tratar de hacer cosas interesantes con lo aprendido.
Aunque aún quedan algunas cosas por aprender sobre HTTP, lo que hemos visto aquí es lo más básico sobre este tema y el conocimiento mínimo requerido para trabajar en proyectos de electrónica que incluyen sistemas de captura y almacenamiento de datos. La información leída por los sensores de un circuito electrónico puede ser enviada a un servidor web utilizando los métodos GET y POST para la transferencia de datos. Pero de ese tema hablaremos en otro post.
Espero que la información presentada sea de su agrado y utilidad. Cualquier comentario o duda me lo dejan en la caja de comentarios.













