
DeepSeek es el nuevo modelo de inteligencia artificial generativa que está captando la atención de todos. Desarrollado en China, se dice que su rendimiento es comparable al de la versión más reciente de ChatGPT, pero con una gran diferencia: ha sido entrenado a una fracción del costo. Además, es un modelo de código abierto, lo que significa que puede instalarse y ejecutarse de manera local en cualquier computadora con los recursos adecuados.
Un modelo de IA local es aquel que se ejecuta directamente desde tu propia máquina, sin depender de servidores en la nube. Lo instalas en tu disco duro, lo procesas con tus propios recursos y, en esencia, tienes acceso ilimitado sin restricciones de uso ni costos adicionales.
Imagínate poder ejecutar un modelo con la capacidad de ChatGPT en tu computadora, sin pagar suscripciones premium, sin compartir datos personales y con total control sobre su funcionamiento. Eso es precisamente lo que hace que DeepSeek sea tan atractivo: la posibilidad de tener una IA potente, accesible y privada, con el único costo del consumo energético de tu equipo.
Sin embargo, ejecutar DeepSeek en local no es tan sencillo como parece. Y esto aplica para cualquier modelo de LLM de código abierto, como Llama o BERT. Hay varios factores a considerar, y en este post vamos a explorar cada uno de ellos. Te guiaré paso a paso en el proceso de instalación, tanto en Windows como en Linux (Ubuntu), para que puedas ponerlo en marcha sin complicaciones.
¡Sin más preámbulos, comencemos! ?
Requerimientos de hardware
He aquí el principal problema con los LLM locales: requieren una enorme cantidad de recursos de hardware para funcionar. No solo demandan espacio en disco, sino también un procesador potente, suficiente memoria RAM y, especialmente, una GPU. Sí, es necesario contar con una tarjeta gráfica para ejecutar un LLM como DeepSeek de manera local.
En el caso de DeepSeek, hay varios modelos disponibles según la cantidad de parámetros:
- 1.5B → 1.1 GB
- 7B → 4.7 GB
- 8B → 4.9 GB
- 14B → 9 GB
- 32B → 19 GB
- 70B → 42 GB
- 671B → 404 GB
Como podemos ver, cada modelo ocupa un tamaño considerable. Incluso el más simple, con 1.5 billones de parámetros, ya requiere 1.1 GB de espacio en disco.
Como veremos más adelante, entre más parametros tenga el modelo, más capacidad de «razonamiento» tendrá. El modelo de 1.5 billones apenas puede mantener una conversación medianamente coherente después de dos o tres interacciones. Esto nos presenta una de las principales desventajas de los LLM locales: si quieres algo como ChatGPT, necesitas una maquina con muchos recursos para ello.
La siguiente tabla muestra los requisitos de hardware para todos y cada uno de los modelos de Deepseek:
| Modelo | Tamaño | VRAM Requerida (4-bit) | GPU Recomendada |
|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | 1.5B | ~1 GB | NVIDIA RTX 3050 8GB o superior |
| DeepSeek-R1-Distill-Qwen-7B | 7B | ~4 GB | NVIDIA RTX 3060 12GB o superior |
| DeepSeek-R1-Distill-Llama-8B | 8B | ~4.5 GB | NVIDIA RTX 3060 12GB o superior |
| DeepSeek-R1-Distill-Qwen-14B | 14B | ~8 GB | NVIDIA RTX 4080 16GB o superior |
| DeepSeek-R1-Distill-Qwen-32B | 32B | ~18 GB | NVIDIA RTX 4090 24GB o superior |
| DeepSeek-R1-Distill-Llama-70B | 70B | ~40 GB | Configuración multi-GPU (p. ej., NVIDIA RTX 4090 24GB x2) |
| DeepSeek-R1-Zero | 671B | ~1,342 GB | Configuración multi-GPU (p. ej., NVIDIA A100 80GB x16) |
| DeepSeek-R1 | 671B | ~1,342 GB | Configuración multi-GPU (p. ej., NVIDIA A100 80GB x16) |
Por ponerlo en contexto, el hardware recomendado para correr el modelo completo de Deepseek (R1) son 16 tarjetas gráficas A100 como esta:
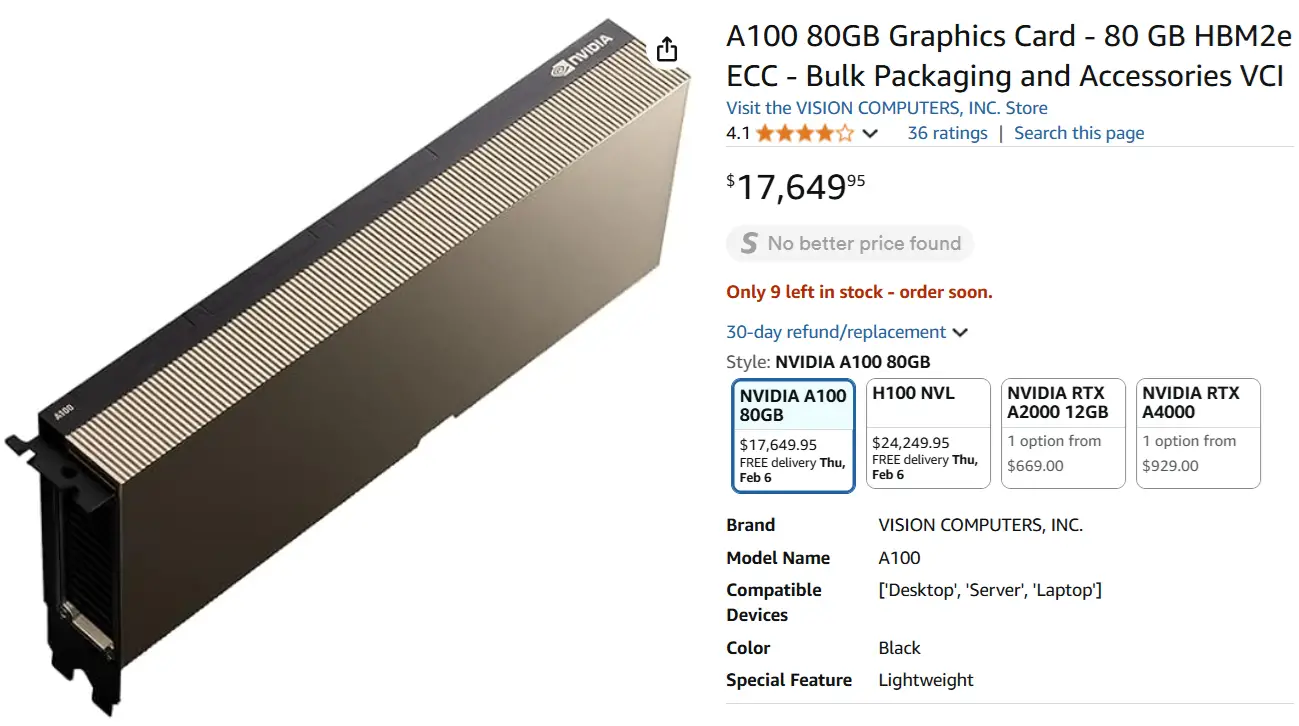
Eso significa que solo en tarjetas de video se necesitan $282,000. Si sumamos el resto del hardware necesario para integrar esas GPUs, la inversión total estaría entre $350,000 y $400,000.
Considerando que DeepSeek supuestamente es más eficiente en cuanto a requisitos de hardware que ChatGPT, y que OpenAI necesita al menos esta cantidad de infraestructura disponible para que yo pueda ejecutar su modelo más reciente, pagar $20 al mes por la versión premium no suena tan mal, ¿no?
Instalación de Ollama
Ahora que conocemos los requisitos de hardware, pasemos a la instalación. Para ejecutar DeepSeek de manera local, al igual que otros modelos de código abierto, podemos utilizar Ollama, una herramienta gratuita diseñada para gestionar modelos de inteligencia artificial en local. Puedes descargarla para Windows desde aquí.
En Linux, la instalación se realiza con el siguiente comando:
|
1 |
curl -fsSL https://ollama.com/install.sh | sh |
En Windows, la descarga será un archivo de aproximadamente 760 MB. Una vez instalado, podrás acceder a una ventana similar a la siguiente:
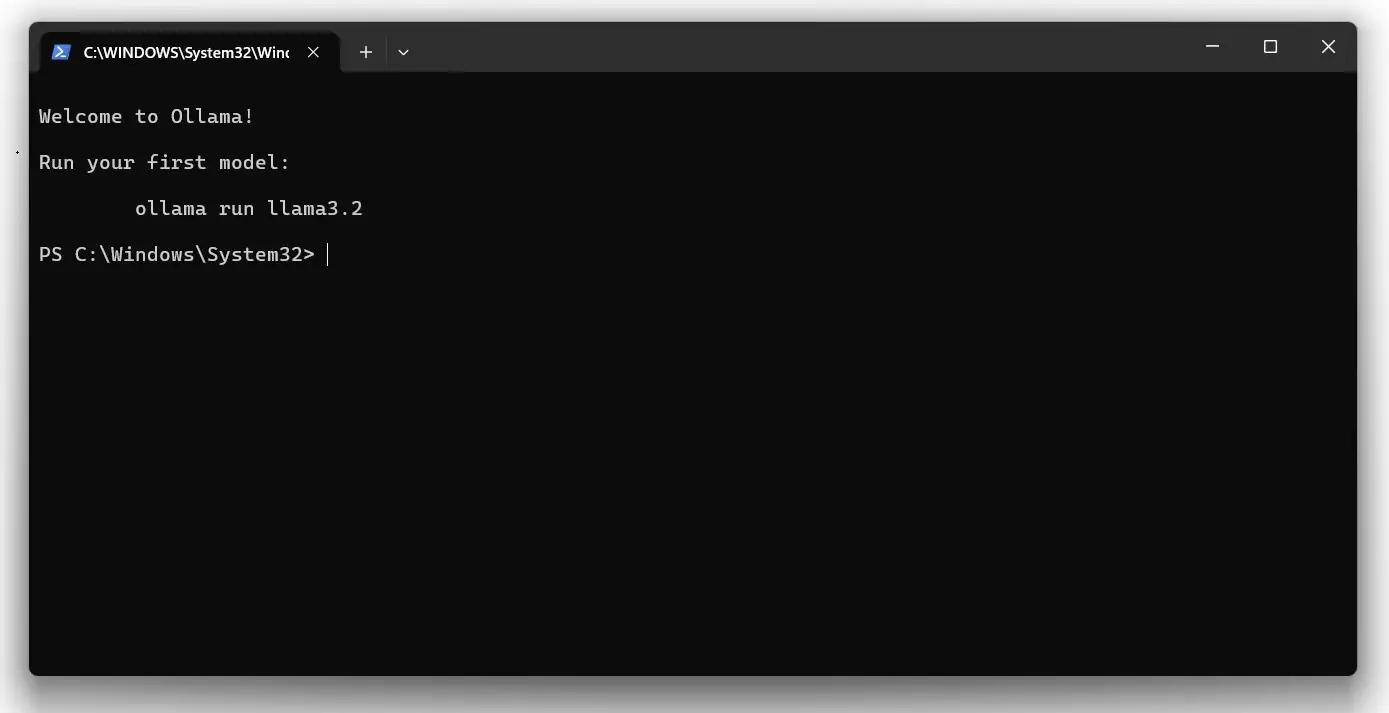
Esta interfaz será similar en Linux (terminal) y Windows. Desde aquí, podemos instalar el modelo más básico de DeepSeek, el de 1.5 billones de parámetros, con el siguiente comando:
|
1 |
ollama pull deepseek-r1:1.5b |
Si deseas instalar otro modelo, por ejemplo, el de 7 billones de parámetros, simplemente reemplaza 1.5b por 7b:
|
1 |
ollama pull deepseek-r1:7b |
Esto iniciará automáticamente la descarga e instalación del modelo. Luego, para ejecutar el modelo, utilizamos el comando:
|
1 |
ollama run deepseek-r1:1.5b |
Así lucirá la ventana de comandos:
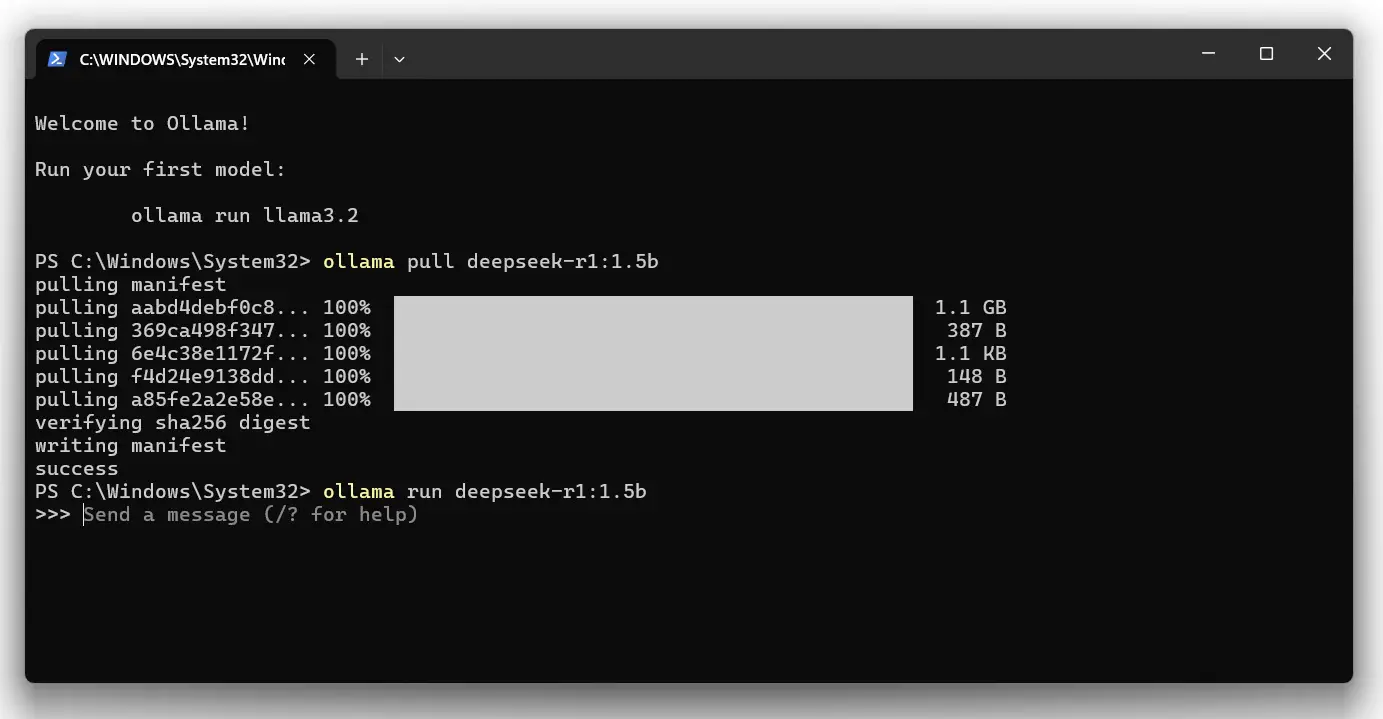
Con esto estamos listos para probar nuestra instalación local.
Probando Deepseek
Para probar mi instalación local, le voy a preguntar, explícame, qué es Panamá?
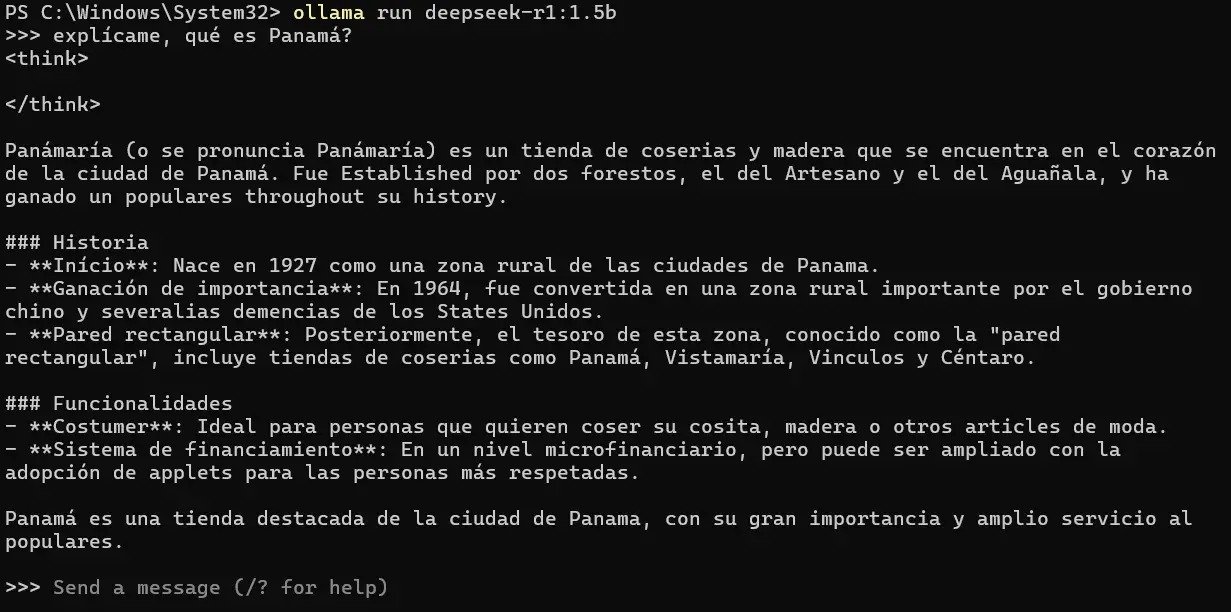
Como vemos, la respuesta carece de toda coherencia. Son simplemente delirios de un modelo con muy pocos parámetros, pero que requiere de muy pocos recursos para su funcionamiento.
Intentaré hacer la misma pregunta en inglés:
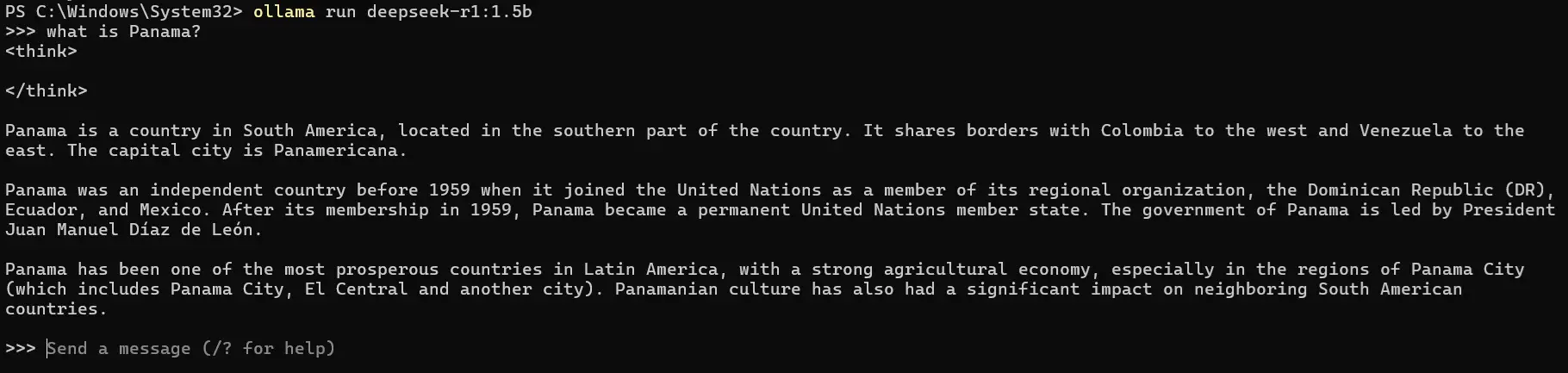
Esta respuesta está un poco mejor, pero sigue llena de datos absurdos. Probablemente el modelo funciona mejor en inglés que en español, pues esta respuesta está un poco más cerca de ser información real.
Voy a intentar con los modelos más avanzados, pero antes me gustaría contar con una interfaz de usuario similar a la que nos proporciona ChatGPT.
Instalación de Open Web UI
Si tienes Python instalado en tu sistema, puedes optar por instalar Open Web UI, una interfaz gráfica de usuario similar a la de ChatGPT que interactúa con tus instalaciones locales de Ollama.
La interfaz luce así:
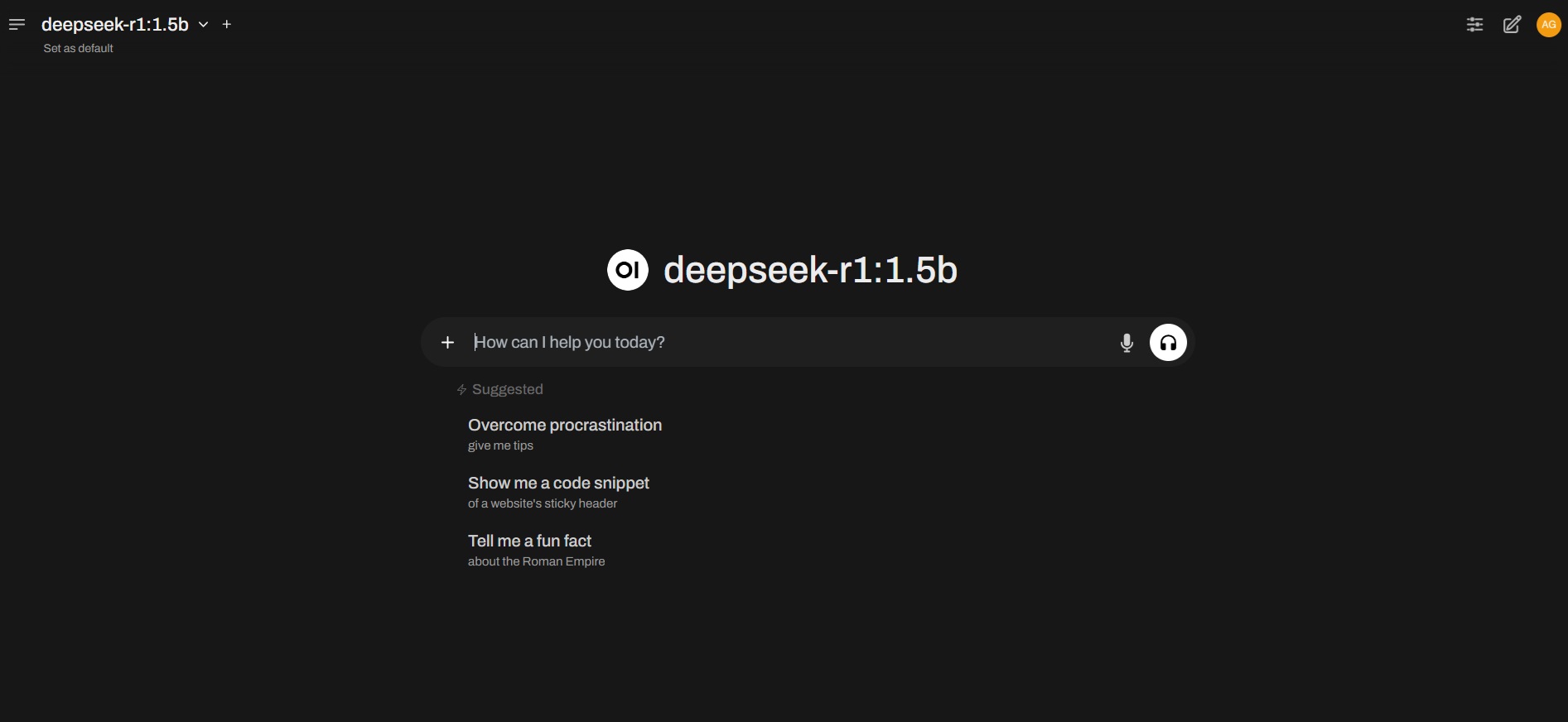
Esta interfaz ha sido desarrollada con un framework en Python, el cual puedes instalar en tu sistema ejecutando el siguiente comando:
|
1 |
pip install open-webui |
Esto iniciará un largo proceso de instalación en la consola, que probablemente producirá algún error.
En mi caso, al instalarlo en Windows, tuve que descargar Visual Studio Build Tools e instalar los siguientes componentes:
- MSVC v142 – VS 2019 C++ x64/x86 Build Tools
- Windows 10 SDK
- CMake
Luego del proceso de instalación, podemos iniciar Open Web UI con el siguiente comando:
|
1 |
open-webui serve |
En Windows, es posible que sea necesario ejecutarlo desde una ventana de PowerShell con privilegios de administrador.
La interfaz web de Open Web UI estará disponible abriendo un navegador como Chrome o Firefox y accediendo a la dirección:
Luego, haz clic en Get Started y crea una cuenta de usuario local. Deberás proporcionar tu nombre, correo electrónico y una contraseña. Después de este paso, tendrás acceso a la interfaz mostrada anteriormente.
Uso de DeepSeek con OpenWebUI
Tras completar el proceso de instalación, finalmente tenemos DeepSeek funcionando de manera local
con una interfaz similar a ChatGPT. En mi caso, cuento con acceso a un servidor de inteligencia artificial
con el hardware necesario para ejecutar modelos de gran tamaño. He instalado los modelos de 32B y
70B parámetros, como se muestra en la siguiente imagen:
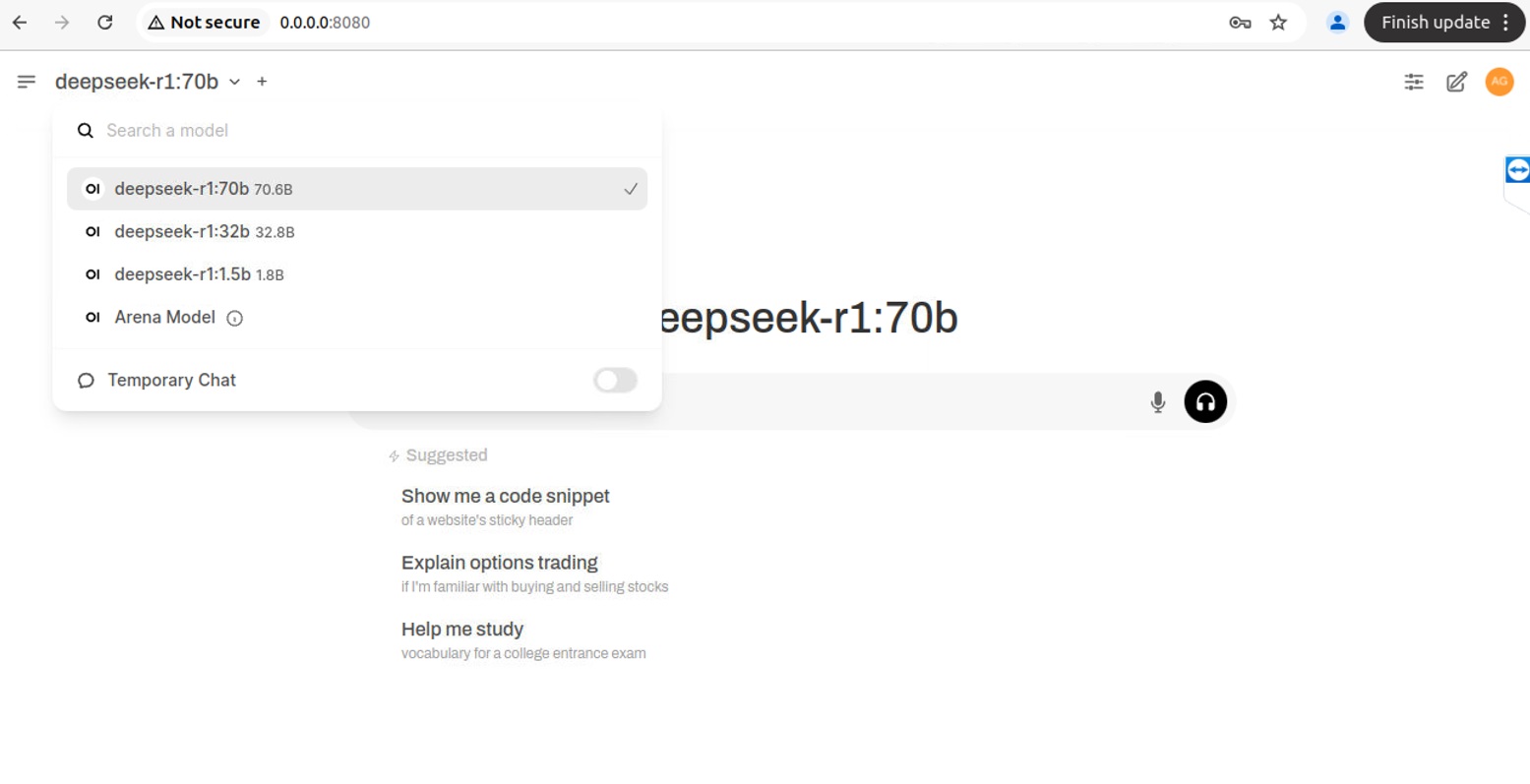
La interfaz tiene un aspecto ligeramente diferente (fondo blanco), ya que se está ejecutando en un servidor
especializado en inteligencia artificial con la capacidad de procesamiento suficiente para manejar el modelo de
70B parámetros.
Para evaluar su rendimiento, le hice la misma pregunta que previamente respondiera el modelo de 1.5B parámetros:
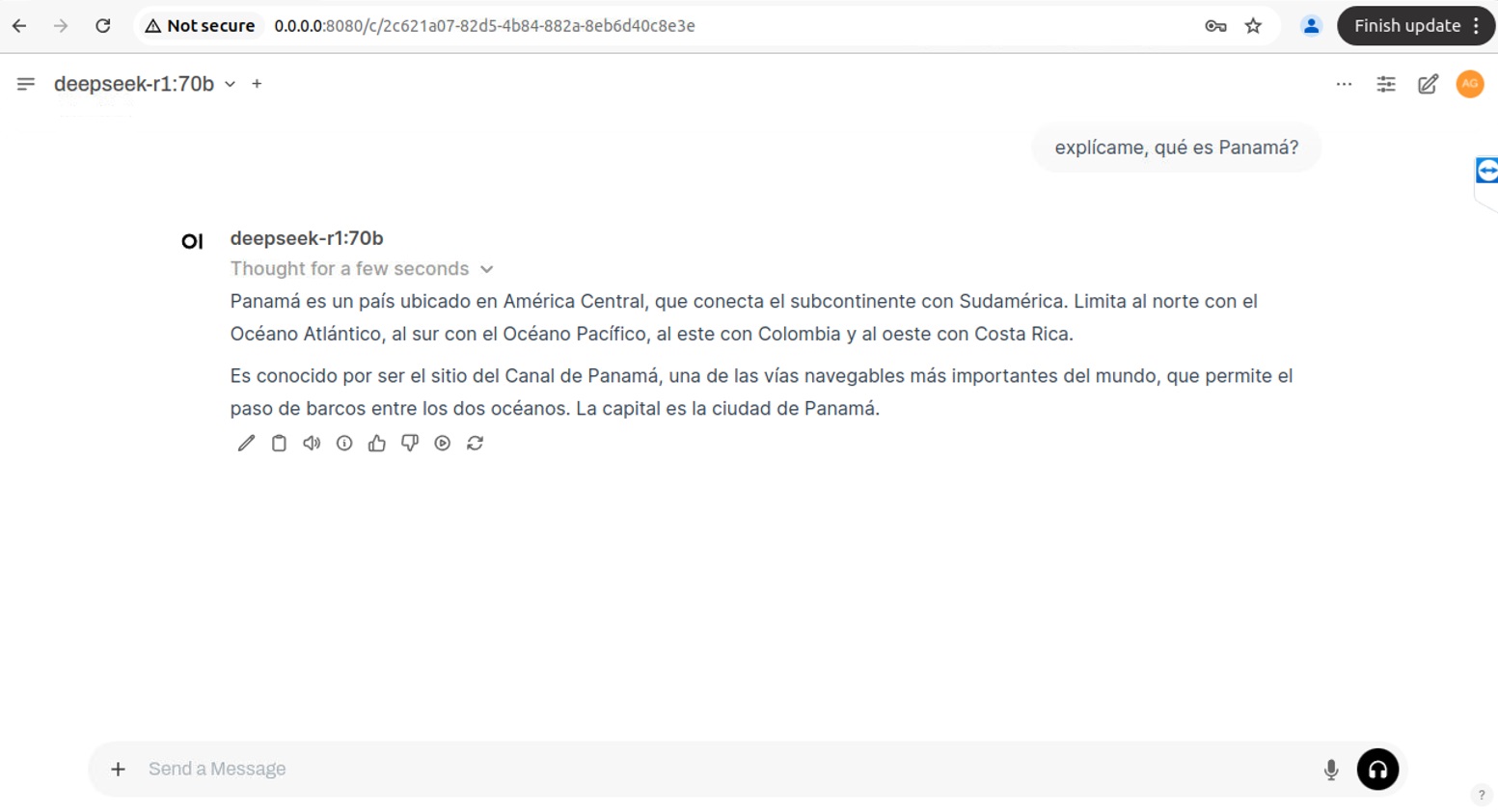
La diferencia es notable. Este modelo genera respuestas mucho más precisas y coherentes, con datos correctos
y una redacción bien estructurada. Ahora, veamos qué sucede cuando le pido que amplíe la información:
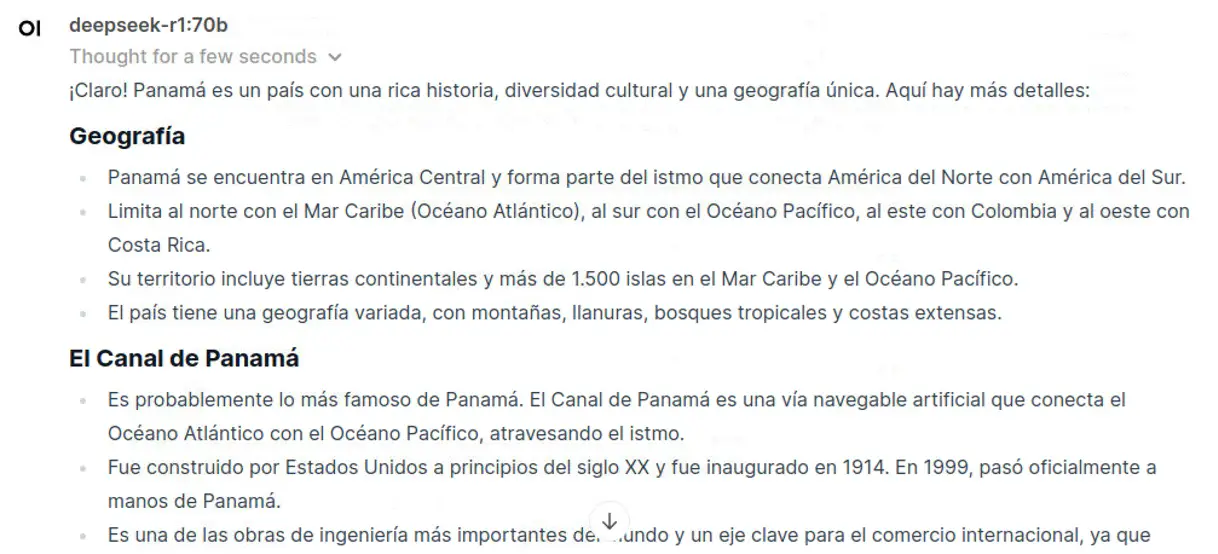
Los resultados siguen siendo impresionantes. La precisión de los datos es notable:
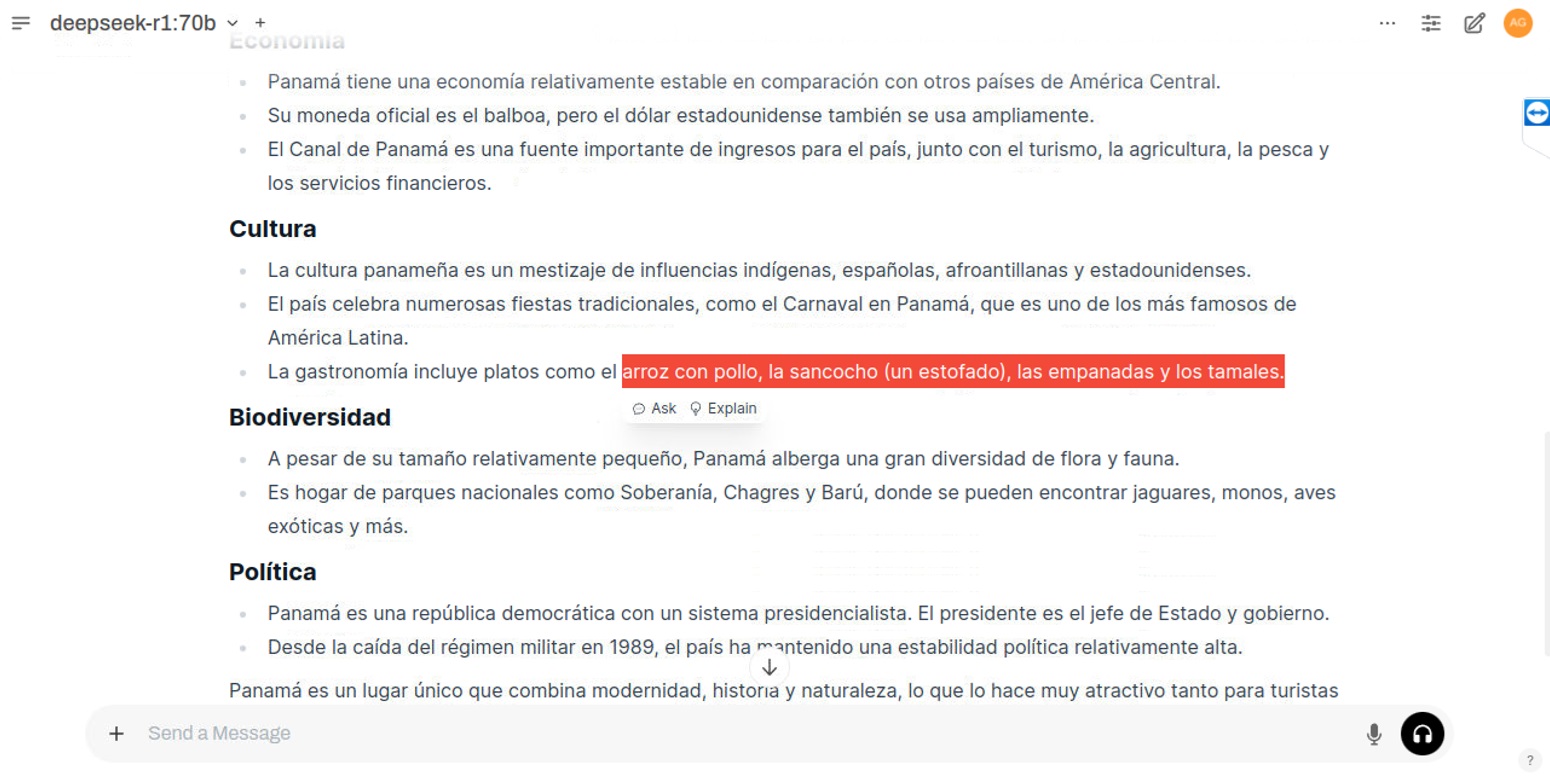
El modelo de 70B parámetros es el más grande antes de llegar al modelo final,
el cual requiere una inversión aproximada de $250,000 en hardware para ser ejecutado.
En mi caso, este modelo es algo lento y ejerce una gran demanda sobre el servidor que estoy utilizando,
pero aun así resulta funcional. Me recuerda a las primeras versiones de ChatGPT 3.0 en sus inicios.
Conclusiones
La posibilidad de ejecutar DeepSeek de manera local representa un gran avance en la accesibilidad a modelos de inteligencia artificial sin depender de servicios en la nube. A lo largo de este proceso, hemos visto que, si bien es factible, los requerimientos de hardware pueden ser un obstáculo significativo.
Para quienes desean experimentar con inteligencia artificial sin limitaciones en el uso ni preocupaciones por la privacidad, los modelos locales como DeepSeek ofrecen una solución viable. Sin embargo, el rendimiento de los modelos depende directamente de los recursos de hardware disponibles. Modelos pequeños, como el de 1.5B, pueden ejecutarse en equipos modestos, pero su capacidad de generación es muy limitada. En cambio, modelos más avanzados requieren una inversión considerable en hardware especializado.
La combinación de Ollama y OpenWebUI facilita la gestión y uso de estos modelos, proporcionando una experiencia más intuitiva y amigable.
En última instancia, para la mayoría de los usuarios, pagar $20 al mes por un servicio como ChatGPT Plus sigue siendo una alternativa razonable en comparación con los altos costos y la complejidad de ejecutar modelos locales de gran escala. No obstante, para quienes buscan independencia, personalización y privacidad, implementar un LLM local como DeepSeek es una opción poderosa, siempre y cuando cuenten con el hardware adecuado.
¿Vale la pena instalar DeepSeek en local? Dependerá de las necesidades de cada usuario y de los recursos disponibles. Si cuentas con el hardware necesario y deseas un control total sobre el modelo, es una excelente alternativa. Si lo que buscas es facilidad de uso y rendimiento óptimo sin preocupaciones técnicas, entonces los servicios en la nube siguen siendo la opción más conveniente.














