
En este post empezaremos a explorarlas características del dataset MNIST en Python. En los días que vivimos, Machine Learning se ha convertido en el tema de moda. Los algoritmos de inteligencia artificial te permiten hacer procesamiento de datos de formas que hace algunos años habrían resultado muy difíciles o incluso imposibles.
Para trabajar en Machine Learning, una de las principales herramientas son las librerías disponibles en Python, especialmente diseñadas para este propósito. Pero para probar los algoritmos de Machine Learning hace falta contar con datos de prueba que permitan comprobar el performance de tu algoritmo.
En Internet existe toda clase de colecciones de datos diseñadas para este propósito. Uno de los datasets más utilizados es el MNIST, formado por decenas de miles de imágenes de números manuscritos.
 Sobre este tema hablamos brevemente en nuestro post anterior: Importar archivos CSV en Python.
Sobre este tema hablamos brevemente en nuestro post anterior: Importar archivos CSV en Python.
En este post lo que haremos será explorar un poco más a fondo el dataset MNIST para ver como lo podemos utilizar en nuestras pruebas con algoritmos de Machine Learning.
En primer lugar debemos saber que MNIST lo podemos descargar en formato CSV en el siguiente enlace: dataset de entrenamiento, dataset de prueba, dataset original. Los dataset de entrenamiento y prueba serán los que estaremos revisando en este post.
El dataset de entrenamiento cuenta con 60,000 registros y el de prueba cuenta con 10,000. Ambos están en formato CSV, donde la primera columna cuenta con las etiquetas de datos y las siguiente 784 columnas cuenta con los pixeles de cada imagen. Estas 784 columnas pueden ser formateadas para reconstruir las imágenes de 28×28 pixeles que forman el dataset.
En Github he creado un repositorio en nuestra cuenta de Panama Hitek en el que trataré de incluir los códigos utilizados en las distintas publicaciones sobre Machine Learning. Ya he agregado el script sobre cómo cargar archivos CSV en Python. En este post lo que haremos será tratar de convertir los pixeles almacenados en los datasets de MNIST en imágenes que puedan ser visualizadas. El código sería el siguiente:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import pandas as pd import numpy as np import matplotlib.pyplot as plt def loadDataset(fileName, samples): x = [] y = [] train_data = pd.read_csv(fileName) y = np.array(train_data.iloc[0:samples, 0]) x = np.array(train_data.iloc[0:samples, 1:]) return x,y x,y=loadDataset("../datasets/mnist/mnist_train.csv",100) digit = x[0] digit_pixels = digit.reshape(28, 28) plt.imshow(digit_pixels, cmap='gray') plt.show() |
En este código se utiliza la función presentada en nuestro post anterior (loadDataset). En la variable digit se almacenan los datos de la primera fila de datos, entre la columna 1 y 785. Esta fila se formatea como una matriz 28 x 28 y se almacena en digit_pixels. Esta matriz es convertida en una imagen en escala de grises utilizando la función imshow del objeto plt. Finalmente se muestra el contendio del objeto plt con la función show().
Al ejecutar este código, el resultado es el siguiente:
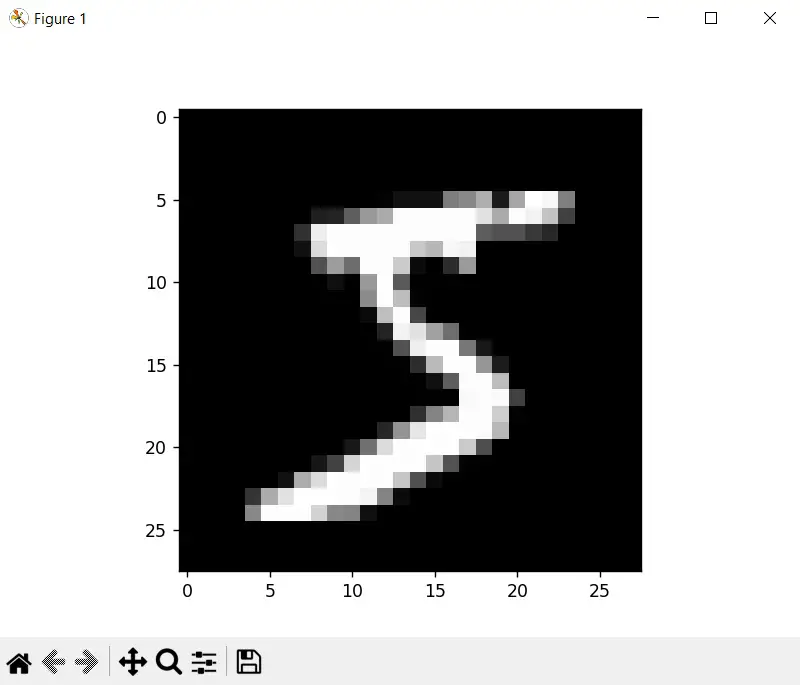 Esta imagen nos presenta un «cero» manuscrito. Si revisamos el dataset de pruebas (mnist_train.csv) en Excel, veremos lo siguiente:
Esta imagen nos presenta un «cero» manuscrito. Si revisamos el dataset de pruebas (mnist_train.csv) en Excel, veremos lo siguiente:
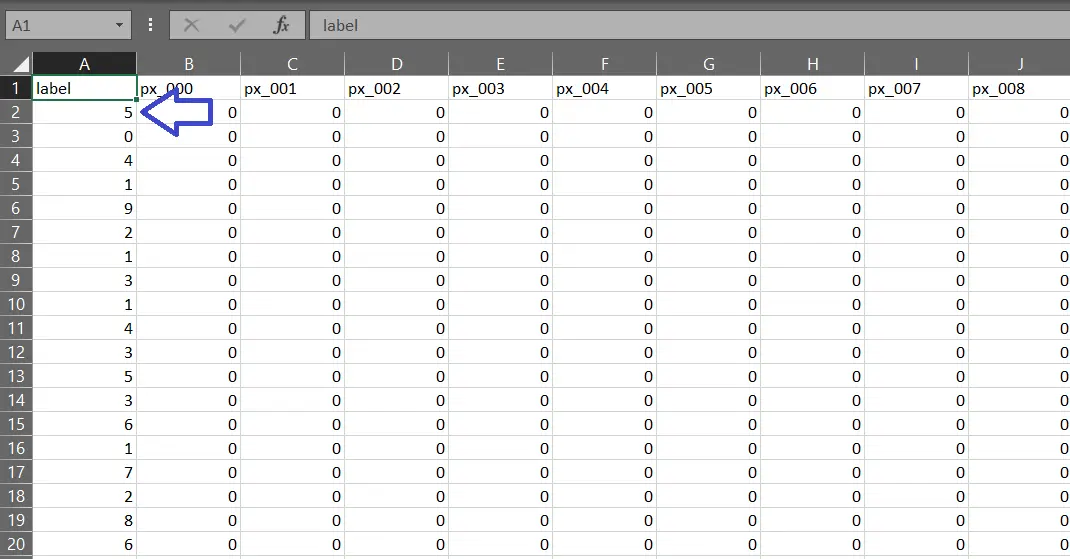
Si cambiamos el índice en la línea digit = x[0] podremos visualizar otros dígitos. Por ejemplo, con el índice 1 veremos un cero. El índice 2 nos mostrará un 4. Luego un 1, 9, 2… y así sucesivamente.

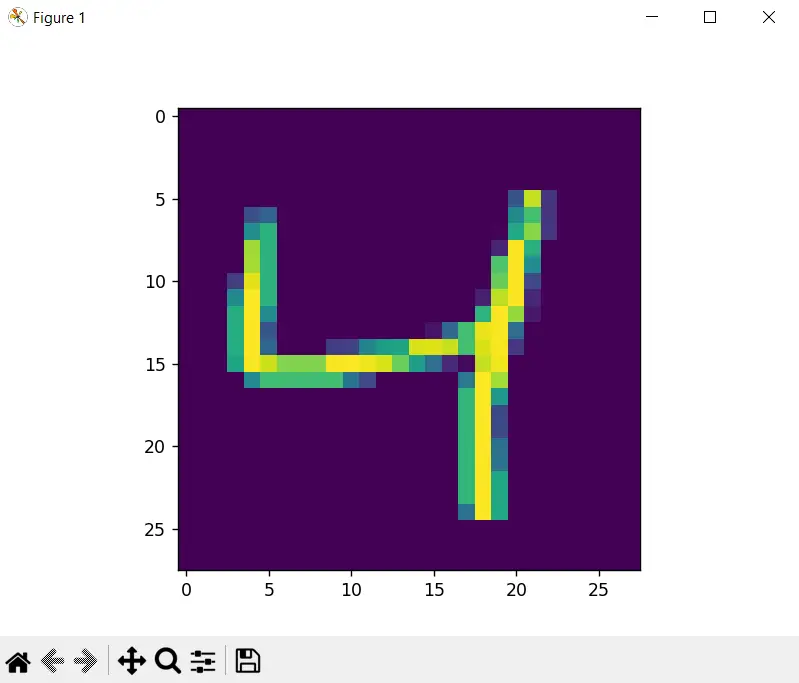
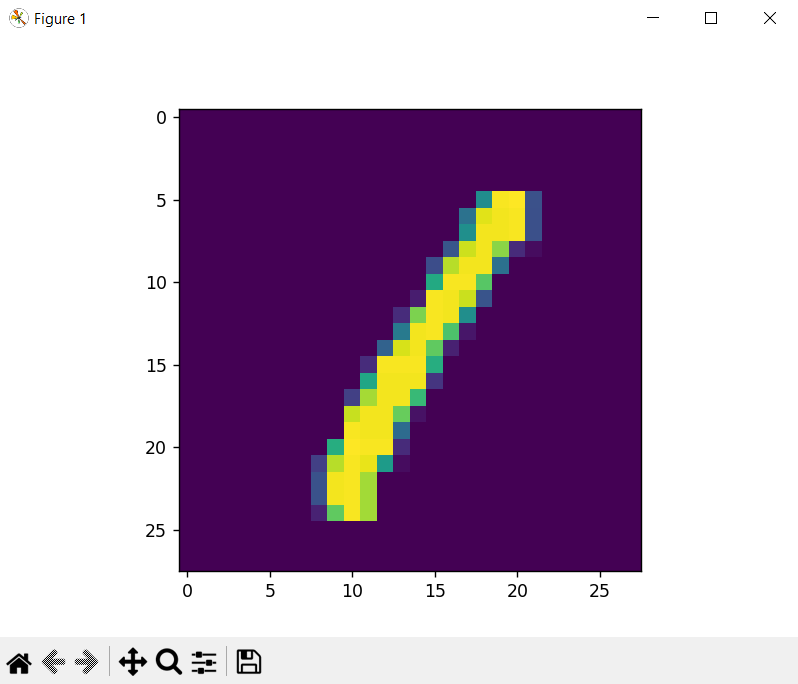

Para que los números sean visualizados en colores, tales como los que he mostrado aquí, se debe utilizar la instrucción plt.imshow(digit_pixels) en vez de plt.imshow(digit_pixels, cmap=’gray’).
Cabe destacar que todos y cada uno de los números manuscritos en este dataset son distintos entre sí. Por ejemplo, en los índices 2, 9, 20, 26, 53 y 58 hay caracteres que representan el número 4. Veamos como lucen:
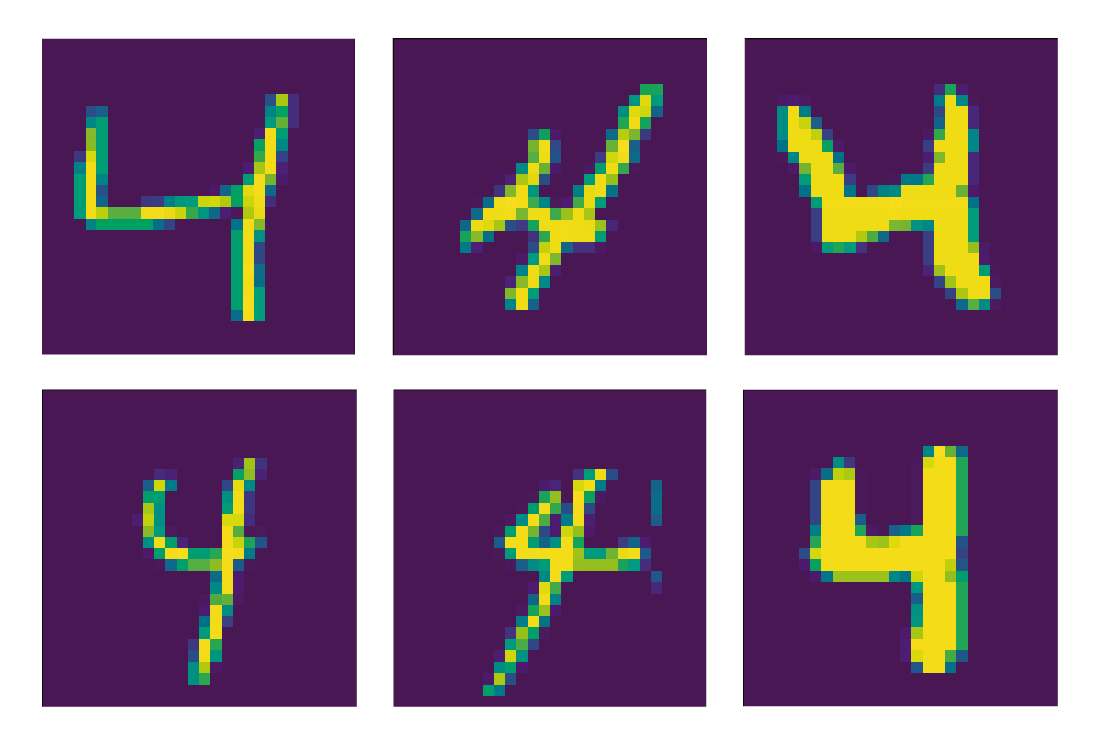
Como vemos, cada uno de los caracteres es distinto a los otros. Si fuesen iguales, el entrenamiento del modelo de Machine Learning no sería efectivo. En nuestras próximas publicaciones empezaremos a hacer pruebas con los clasificadores, que nos permitirán discriminar la mayor parte de estas imágenes:
- ¿Cómo construir un clasificador de imágenes con Machine Learning en Python?
- Analizando mi escritura con Machine Learning en Python
- Implementación de un clasificador Random Forest en Python
- Probando el clasificador K-Nearest Neighbors con el dataset MNIST
- Optimización de hiperparámetros de un clasificador de Machine Learning en Python
- Selección de algoritmos de clasificación de Machine Learning en Python
- Redes Neuronales con Tensorflow en Python
- PyTorch y MNIST: Cómo entrenar una red neuronal para clasificación de imágenes
Recientemente hemos agregado una sección completa en la que condensamos todos los contenidos sobre Machine Learning y las múltiples pruebas que hemos hecho con el MNIST dataset. Los invito a visitarla y a revisar los contenidos que constantemente estamos publicando sobre estos temas de interés.
Conclusión
En conclusión, este post proporciona un tutorial detallado sobre cómo utilizar el dataset MNIST en Python para Machine Learning. El autor explica de manera clara y concisa cómo descargar y cargar los datos en formato CSV, así como cómo utilizar las librerías pandas, numpy y matplotlib para convertir los pixeles de las imágenes en una representación gráfica que puede ser visualizada.
En resumen, este post proporciona una guía valiosa para aquellos que están interesados en utilizar el dataset MNIST para experimentar con algoritmos de Machine Learning en Python. Es importante destacar que el autor también ha compartido el código utilizado en este tutorial en un repositorio en Github, lo que facilita el uso y la comprensión del tutorial.
Por último, quiero agradecer a los lectores por tomarse el tiempo de leer este post y espero que hayan encontrado útil la información proporcionada. Si tienen alguna pregunta o comentario, estaré encantado de responderlos en la sección de comentarios. Invito a todos a compartir sus experiencias y conocimientos sobre el uso del dataset MNIST en Python, ya que esto ayudará a enriquecer nuestra comunidad de aprendizaje en Machine Learning.











