
¿Te has preguntado alguna vez cómo seleccionar los mejores hiperparámetros para tu modelo de Machine Learning? La optimización de hiperparámetros es una parte importante del proceso de construcción de un modelo de aprendizaje automático, ya que puede tener un gran impacto en el rendimiento del modelo. Pero, ¿qué son exactamente los hiperparámetros y para qué se utilizan?
Los hiperparámetros son los parámetros de un modelo de aprendizaje automático que no se aprenden directamente a partir de los datos. Por ejemplo, en un clasificador de árboles de decisión, un hiperparámetro podría ser la profundidad máxima de cada árbol en el bosque. Los hiperparámetros se establecen antes de entrenar el modelo y se utilizan para controlar el comportamiento del modelo.
En este artículo, hablaremos sobre la importancia de la optimización de hiperparámetros y cómo se puede utilizar la herramienta GridSearchCV de Sklearn para encontrar los mejores hiperparámetros para un clasificador de Random Forest.
Aquí en Panama Hitek ya hemos escrito antes sobre el clasificador Random Forest como parte de las publicaciones de nuestra sección de Machine Learning. Hasta ahora hemos logrado los siguientes resultados con Random Forest:

En un principio utilizamos los hiperparámetros por default del classificador Random Forest y logramos un 96.82% de precisión en la clasificación del dataset MNIST. Luego, utilizando 200 n_estimators como hiperparámetro logramos aumentar la precisión a 97.02%. El aumento fue marginal, pero aún así mejor que los parámetros por default.
Definición de hiperparámetros
En el contexto del aprendizaje automático, los hiperparámetros son los parámetros de un modelo que no se aprenden a partir de los datos. Se establecen antes de entrenar el modelo y se utilizan para controlar el proceso de aprendizaje y el comportamiento del modelo. Los hiperparámetros a menudo se eligen a través de un proceso llamado optimización de hiperparámetros, en el que se entrena y evalúa el modelo utilizando una variedad de valores de hiperparámetros diferentes y se selecciona el mejor conjunto de valores en base al rendimiento del modelo.
Cada modelo de Machine Learning cuenta con sus propios hiperparámetros. Por ejemplo, en una red neural, algunos hiperparámetros comunes incluyen la tasa de aprendizaje, el número de capas ocultas y el número de neuronas en cada capa oculta.
En el caso de un clasificador Random Forest, los principales hiperparámetros son:
-
- n_estimators: El número de árboles en el bosque.
- criterion: La función de pérdida que se utiliza para medir la calidad de una división. Los valores posibles son «gini» (impureza de Gini) y «entropy» (entropía).
- max_depth: La profundidad máxima de cada árbol en el bosque. Si se establece en None, los árboles se expanden hasta que todas las hojas sean puros o hasta que se alcance el límite máximo de hojas.
- min_samples_split: El número mínimo de muestras necesarias para dividir un nodo interno.
- min_samples_leaf: El número mínimo de muestras necesarias para estar en una hoja.
- min_weight_fraction_leaf: El porcentaje mínimo de la suma total de pesos (en el conjunto de entrenamiento) requerido para estar en una hoja.
- max_leaf_nodes: El número máximo de hojas en un árbol. Si se establece en None, los árboles se expanden hasta que todas las hojas sean puros o hasta que se alcance el límite máximo de hojas.
- min_impurity_decrease: La cantidad mínima de impureza que se debe reducir para permitir la división de un nodo.
- class_weight: Pesos opcionales para cada clase. Si se proporciona, se ajusta el modelo de forma más equilibrada para las clases con pesos más altos.
- bootstrap: Si se establece en True, se utiliza el muestreo con reemplazo al construir cada árbol. Si se establece en False, se utiliza el conjunto completo de entrenamiento para cada árbol.
- oob_score: Si se establece en True, se calcula el puntaje de out-of-bag (OOB) para evaluar el modelo.
- n_jobs: El número de trabajos paralelos a utilizar al entrenar el modelo. Si se establece en -1, se utilizan todos los procesadores disponibles.
- random_state: Semilla aleatoria para controlar la aleatoriedad del modelo.
- verbose: Si se establece en 1, se muestran mensajes de progreso durante el entrenamiento.
- warm_start: Si se establece en True, se reutilizan los árboles existentes al agregar más árboles al bosque, lo que permite un entrenamiento más rápido. Si se establece en False, se construye un nuevo bosque desde cero cada vez que se llama al método fit.
Cuando no se especifica algún parámetro de los aquí listados para un clasificador Random Forest se asume un valor por defecto. También cabe resaltar que algunos hiperparámetros son más importantes que otros y que resulta muy complicado tratar de optimizarlos todos a la vez, pues para cada set de parámetros hace falta hacer una prueba con el dataset en cuestión.
El GridSearchCV de Sklearn
GridSearchCV es una clase de la biblioteca de aprendizaje automático Sklearn que se utiliza para ajustar un modelo a un conjunto de datos de entrenamiento utilizando diferentes valores de hiperparámetros. Funciona evaluando cada posible combinación de valores de hiperparámetros y seleccionando la mejor combinación según la puntuación obtenida en una división de validación cruzada.
El GridSearchCV se inicializa con el modelo que se va a ajustar, un diccionario de hiperparámetros y el número de divisiones para la validación cruzada. Luego, se llama al método fit con el conjunto de datos de entrenamiento y GridSearchCV evalúa cada combinación de hiperparámetros utilizando la validación cruzada y selecciona la mejor combinación. Una vez que se haya entrenado el modelo, se puede utilizar el método predict para hacer predicciones con el modelo ajustado.
En resumen, GridSearchCV es una herramienta útil para optimizar los hiperparámetros de un modelo de aprendizaje automático evaluando diferentes combinaciones de hiperparámetros y seleccionando la mejor combinación según la puntuación obtenida en una validación cruzada. Es una forma efectiva de ajustar un modelo a un conjunto de datos de entrenamiento y mejorar su rendimiento en tareas de predicción.
A continuación presentaré un script en Python para la optimización de hiperparámetros de un clasificador Random Forest utilizando el dataset MNIST. Este script se encuentra disponible en nuestro repositorio de Github:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
from sklearn.model_selection import GridSearchCV import pandas as pd import numpy as np from sklearn.ensemble import RandomForestClassifier trainingSamples = 50000 # Self explanatory """ Here I set the global variables, which will be used to test the computing time for both training and testing """ def loadDataset(fileName, samples): # A function for loading the data from a dataset x = [] # Array for data inputs y = [] # Array for labels (expected outputs) train_data = pd.read_csv(fileName) # Data has to be stored in a CSV file, separated by commas y = np.array(train_data.iloc[0:samples, 0]) # Labels column x = np.array(train_data.iloc[0:samples, 1:]) / 255 # Division by 255 is used for data normalization return x, y # Define the grid of hyperparameter values to search over param_grid = { 'n_estimators': [100, 200, 300, 400, 500], 'max_depth': [None, 10, 20, 30], 'min_samples_split': [2, 5, 10] } # Define the scoring metric to use for evaluation scoring = 'accuracy' # Create a GridSearchCV object clf = RandomForestClassifier() grid_search = GridSearchCV(estimator=clf, param_grid=param_grid, scoring=scoring, cv=3, verbose=2) train_x,train_y = loadDataset("../../../../datasets/mnist/mnist_train.csv",10000) test_x,test_y = loadDataset("../../../../datasets/mnist/mnist_test.csv",10000) # Fit the grid search object to the training data grid_search.fit(train_x, train_y) # Print the best hyperparameters and the best score print("Best hyperparameters:", grid_search.best_params_) print("Best score:", grid_search.best_score_) # Re-train the model with the best hyperparameters best_clf = grid_search.best_estimator_ best_clf.fit(train_x, train_y) # Test the model with the best hyperparameters on the testing data accuracy = best_clf.score(test_x, test_y) print("Testing accuracy:", accuracy) |
Este algoritmo prueba distintas combinaciones de hiperparámetros, escogiendo entre los valores establecidos n_estimators, max_depth y min_samples_split (ver variable param_grid).
La cantidad de pruebas que se harán y el tiempo que esto tardará depende de la cantidad de hiperparámetros que se probarán y del valor de la variable cv (en este caso, cv=3). Esta última especifica la cantidad de veces que cada prueba se repetirá para cada set de parámetros.
En el caso del ejemplo mostrado, estos serán los valores que se probarán:
param_grid = {
‘n_estimators’: [100, 200, 300, 400, 500],
‘max_depth’: [None, 10, 20, 30],
‘min_samples_split’: [2, 5, 10]
}
Tenemos 5 valores distintos de estimadores, 4 de depth y 3 de samples split. También establecimos el cv=3. Dicho esto, nuestro algoritmo hará 5x4x3x3 = 180 pruebas. El tiempo de duración de cada prueba depende de los parámetros que se estén probando.
Hace un rato corrí este algoritmo antes de empezar a escribir y se tardó alrededor de una hora en terminar. Este fue el resultado:
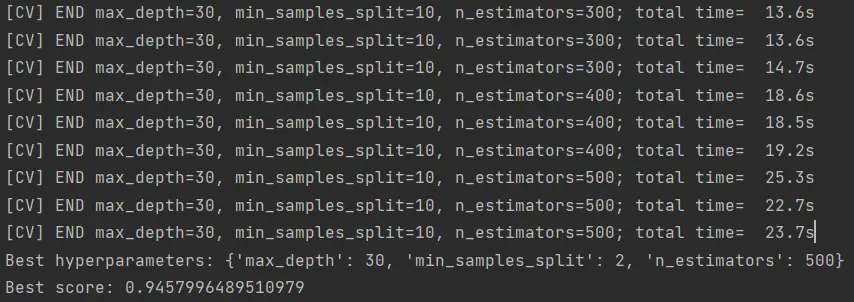 Tal parece que el mejor set de parámetros que se encontró fue:
Tal parece que el mejor set de parámetros que se encontró fue:
RandomForestClassifier(n_estimators=500, max_depth=30,min_samples_split=2)
Nótese que la prueba la hice con 10,000 muestras en el dataset de entrenamiento, pues utilizar más muestras implica más tiempo para ejecutar todas las pruebas. No es fácil esperar 6 horas a que un algoritmo de estos termine de probar todas las combinaciones posibles de parámetros.
Cuando probé los parámetros obtenidos con el dataset MNIST, este fue el resultado:
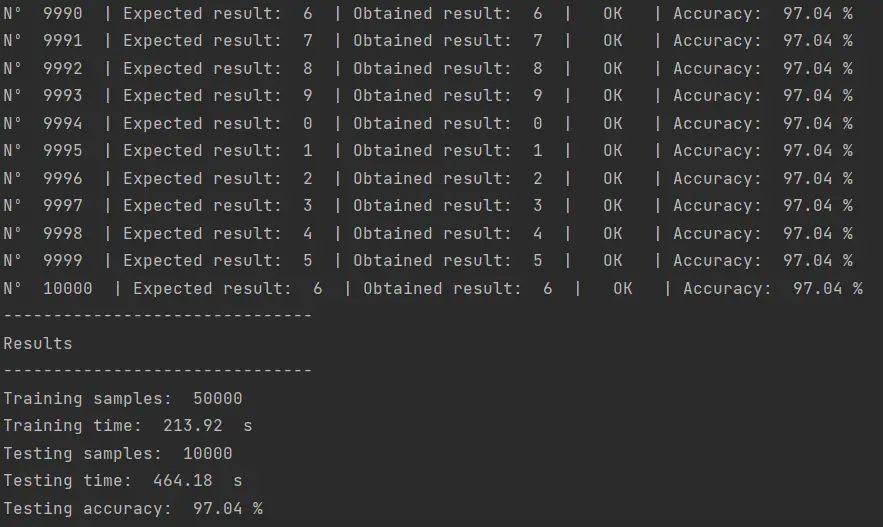
Utilizando n_estimators=200 como único hiperparámetro logré obtener 97.02%. Luego del proceso de optimización de hiperparámetros obtuve 97.04%. Eso son 2 resultados correctos por cada 10,000 muestras, lo cual bien se puede considerar como insignificante.
Es decir, sí, pasamos por el proceso de optimización de hiperparámetros pero no valio la pena. Probablemente los hiperparámetros que escogimos no fueron los más apropiados y nos toca probar con otros parámetros y/o valores. Sin embargo, esto quita mucho tiempo y probablemente existen mejores formas de hacerlo.
Se me ocurre utilizar algún algoritmo de optimización, como Ant Colony Optimization o algo por el estilo para no tener que probar todas las combinaciones y concentrarnos en las que producen los mejores resultados.
Conclusión
La optimización de hiperparámetros es una parte esencial del proceso de construcción de un modelo de Machine Learning. Los hiperparámetros son parámetros que no se aprenden directamente a partir de los datos y se utilizan para controlar el comportamiento del modelo.
Una herramienta útil para optimizar los hiperparámetros es GridSearchCV, que evalúa diferentes combinaciones de hiperparámetros y selecciona la mejor combinación según el rendimiento en una validación cruzada. En este artículo, hemos discutido cómo utilizar GridSearchCV para optimizar los hiperparámetros de un clasificador Random Forest en Python y cómo esto puede mejorar el rendimiento del modelo.
Espero que hayas encontrado útil esta información sobre la optimización de hiperparámetros y cómo utilizar GridSearchCV para mejorar el rendimiento de tu modelo de Machine Learning. Si tienes alguna pregunta o comentario, no dudes en dejarlos en la caja de comentarios a continuación. ¡Gracias por leer!















