
En el ámbito del aprendizaje automático (Machine Learning), la abundancia de términos y técnicas puede ser abrumadora, y en ocasiones, conceptos diferentes pueden parecer similares. Dos términos que suelen confundirse, pero que son fundamentales entender por separado, son «regresión» y «clasificación».
Machine Learning integra ambas técnicas, pero se aplican en situaciones diferentes y persiguen objetivos distintos. Comprender estas diferencias resulta crucial para seleccionar la técnica adecuada en cada problema y, de esta forma, optimizar los resultados obtenidos.
En este artículo, nos enfocaremos en aclarar las diferencias entre regresión y clasificación, exploraremos sus aplicaciones específicas y discutiremos cómo y cuándo utilizar cada una de estas técnicas en proyectos de Machine Learning.
Conceptos básicos
En la imagen se muestra una representación gráfica que ilustra la diferencia entre clasificación y regresión. Un algoritmo de regresión en Machine Learning busca estimar valores numéricos y desarrollar un modelo matemático que se adecue a la mayoría de los puntos azules.
Esto significa que, al proporcionarle una serie de puntos, el algoritmo de regresión intenta generar un modelo que trace la línea roja que se observa en la imagen.
Por otro lado, los algoritmos de clasificación buscan separar un conjunto de datos en dos o más categorías, de ahí el término «clasificación». En el ejemplo de la imagen, se presentan dos clases: círculos morados y cuadrados amarillos. El objetivo del modelo de clasificación es diferenciar los datos y asignar cada muestra a la categoría que el algoritmo estima como pertinente.
La siguiente imagen muestra un ejemplo del mundo real que ilustra las diferencias en el uso de un algoritmo de regresión y uno de clasificación.
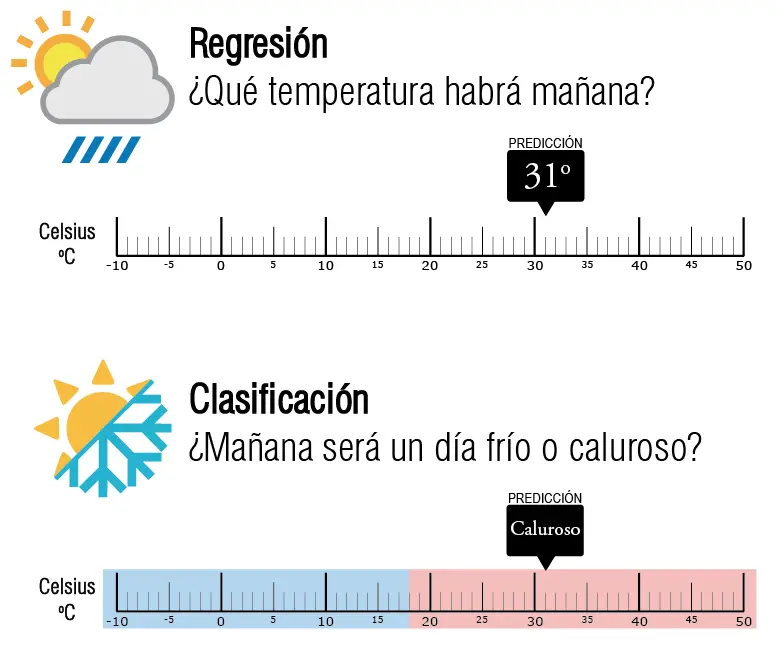
Imaginemos que contamos con dos algoritmos: uno de clasificación y otro de regresión. Estos han sido entrenados para predecir el clima del día siguiente, específicamente la temperatura. El algoritmo de regresión proporcionará un valor específico de temperatura, mientras que el clasificador se limitará a indicar si el día será frío o cálido.
El clasificador se encarga de categorizar un conjunto de datos en clases específicas. Por otro lado, el regresor tiene como objetivo estimar un valor numérico concreto.
Aplicaciones de algoritmos de Regresión
-
-
Predicción de Precios de Bienes Raíces: Un modelo de regresión se puede utilizar para predecir el precio de una vivienda en función de sus características, como el tamaño, el número de habitaciones, la ubicación, etc.
- Predicción de Ingresos: Puedes usar la regresión para predecir los ingresos futuros de un individuo o una empresa en función de variables como la edad, la educación y la experiencia laboral.
-
Análisis de Series Temporales: La regresión es útil para predecir valores futuros en series temporales, como el pronóstico del precio de las acciones, las ventas trimestrales o la demanda de productos a lo largo del tiempo.
-
Predicción de Calidad del Aire: Modelos de regresión pueden predecir la calidad del aire en función de variables como la concentración de contaminantes, la temperatura y la humedad.
-
Estimación de Edad de Personas: Se puede utilizar la regresión para estimar la edad de una persona a partir de características faciales, como en aplicaciones de reconocimiento facial.
-
Aplicaciones de algoritmos de Clasificación
-
-
Detección de Spam: Los filtros de correo no deseado utilizan algoritmos de clasificación para determinar si un correo electrónico es spam o no spam en función del contenido y las características del mensaje.
- Diagnóstico Médico: Los modelos de clasificación pueden ayudar en el diagnóstico médico, como la detección de enfermedades basadas en resultados de pruebas médicas o imágenes médicas.
- Clasificación de Documentos: La clasificación se utiliza para organizar documentos en categorías, como noticias, correos electrónicos, informes, etc., en aplicaciones de gestión de documentos.
- Detección de Fraude en Transacciones Financieras: Los algoritmos de clasificación pueden identificar transacciones fraudulentas en función de patrones de comportamiento y características de transacciones.
- Clasificación de Imágenes: En aplicaciones de visión por computadora, como el reconocimiento de objetos, la clasificación se utiliza para etiquetar objetos en imágenes.
-
Análisis de Sentimientos en Redes Sociales: Los modelos de clasificación pueden determinar si un comentario en una red social es positivo, negativo o neutral, lo que es útil para el análisis de sentimientos.
-
Conclusión
En resumen, en el campo de Machine Learning, es esencial comprender las diferencias entre regresión y clasificación, dos técnicas fundamentales en el aprendizaje supervisado.
La regresión se utiliza para estimar valores numéricos, mientras que la clasificación se emplea para categorizar datos en diferentes clases. Estas técnicas tienen aplicaciones diversas y se seleccionan según el tipo de problema que se enfrenta. Ya sea prediciendo precios de bienes raíces o detectando spam en correos electrónicos, elegir la técnica adecuada es crucial para el éxito de un proyecto de Machine Learning.
Al comprender estas diferencias y aplicaciones, los profesionales pueden tomar decisiones informadas para abordar problemas de manera efectiva y obtener resultados precisos.
Los invito a visitar la parte teórica de este post, Red Wine Quality dataset: ¿Regresión o Clasificación?. Espero les sea de utilidad y les permit aprender nuevos conceptos.

")












