
En este post voy a explicar como podemos configurar una Red Neuronal en Python para utilizarla en la clasificación de imágenes con el MNIST dataset. Esto como parte de mi reciente interés por el tema de Machine Learning.
Las redes neuronales son uno de los modelos de machine learning más interesantes y populares que se conocen en la actualidad. Estas redes pueden aprender a reconocer patrones complejos en los datos, y han demostrado ser eficaces en una amplia variedad de aplicaciones, como el reconocimiento de imágenes y voz, la traducción automática, y la toma de decisiones en tiempo real. Además, las redes neuronales pueden ser entrenadas para mejorar su precisión y rendimiento con el tiempo, lo que las hace ideales para aplicaciones de aprendizaje automático en constante evolución.
Dicho esto, aquí les presentaremos un ejemplo funcional de una red neuronal simple en Python, utilizando Tensorflow, una de las librerías más populares en la actualidad. Sin más que decir, empecemos.
Introducción
Las redes neuronales se inspiran en el funcionamiento del cerebro humano, que está compuesto por miles de millones de células llamadas neuronas, que están interconectadas y trabajan juntas para procesar información y tomar decisiones. De manera similar, las redes neuronales artificiales están compuestas por capas de «neuronas» artificiales que están interconectadas para procesar la información de entrada y producir una salida.
Cada neurona artificial recibe una entrada, que es multiplicada por un peso y sumada a una función de sesgo para producir una salida. Esta salida se utiliza como entrada para otras neuronas, lo que permite a las redes neuronales procesar información de manera muy similar a como lo hace el cerebro humano.
A medida que las redes neuronales se entrenan con más datos, las conexiones entre las neuronas se ajustan para mejorar el rendimiento de la red. Esto permite a la red reconocer patrones complejos en los datos y mejorar su capacidad para realizar tareas de clasificación, predicción y toma de decisiones.
Es importante señalar que en este post no entraremos en detalle sobre la teoría detrás de las redes neuronales. No explicaremos conceptos como las capas, las entradas, la propagación hacia atrás (backpropagation) o los diferentes tipos de funciones de activación. En su lugar, nos centraremos en la implementación de redes neuronales utilizando la biblioteca de TensorFlow en Python. Sin embargo, esperamos en un futuro escribir un post dedicado a este tema, para que puedas profundizar en los conceptos teóricos detrás de las redes neuronales y comprender mejor cómo funcionan.
Tensorflow en Python
TensorFlow es una librería de código abierto para el aprendizaje automático desarrollada por Google. Se utiliza para crear y entrenar modelos de aprendizaje automático, incluyendo redes neuronales, en una variedad de plataformas, incluyendo computadoras portátiles, escritorios y servidores.
TensorFlow es conocido por ser rápido y escalable, lo que lo hace ideal para el entrenamiento de modelos de aprendizaje profundo en grandes conjuntos de datos. Debido a su facilidad de uso y su capacidad para implementar modelos de aprendizaje profundo de forma eficiente, TensorFlow se ha convertido en una de las librerías de aprendizaje automático más populares y ampliamente utilizadas en el mundo.
Además, TensorFlow es compatible con múltiples lenguajes de programación, incluyendo Python, Java, C++ y R, lo que lo hace más accesible para los desarrolladores de diferentes campos y niveles de habilidad. En particular, la interfaz de programación de TensorFlow para Python es una de las más populares y fáciles de usar, lo que ha llevado a un gran número de comunidades de desarrolladores a crear y compartir modelos de aprendizaje automático de código abierto.
La combinación de su facilidad de uso, escalabilidad y versatilidad ha hecho de TensorFlow una de las herramientas más valiosas en el campo del aprendizaje automático.
Clasificador de imágenes basado en red neuronal
Aquí en Panama Hitek ya hemos escrito bastante sobre el MNIST dataset. De hecho, tenemos una sección completa en la que compartimos resultados de pruebas de distintos algoritmos de Machine Learning sobre MNIST:
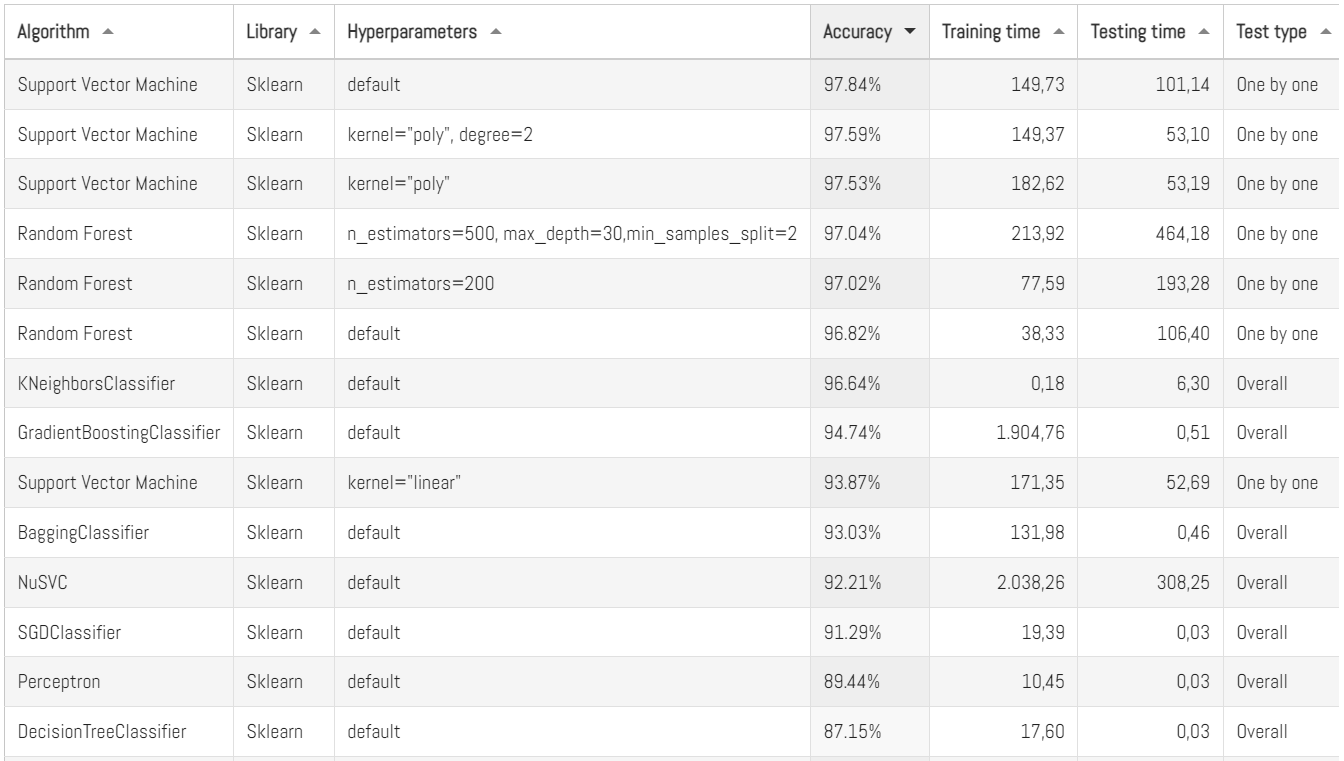
En esta tabla, cada código que hemos probado se encuentra disponible en nuestro repositorio de Github. Hasta ahora hemos estado haciendo pruebas con Sklearn, otra librería muy popular en Machine Learning. Es hora de intentarlo con Tensorflow.
El código que utilizará para probar el algoritmo es el siguiente:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 |
import pandas as pd import numpy as np import time as time import tensorflow as tf trainingSamples = 50000 # Number of samples used for training the model testingSamples = 10000 # Number of samples used for testing the model """ Here I set the global variables, which will be used to measure the computing time for both training and testing """ startTrainingTime = 0 endTrainingTime = 0 trainingTime = 0 startTestingTime = 0 endTestingTime = 0 testingTime = 0 def loadDataset(fileName, samples): """ A function for loading the data from a dataset. """ x = [] # Array for data inputs y = [] # Array for labels (expected outputs) train_data = pd.read_csv(fileName) # Data has to be stored in a CSV file, separated by commas y = np.array(train_data.iloc[0:samples, 0]) # Labels column x = np.array(train_data.iloc[0:samples, 1:]) / 255 # Division by 255 is used for data normalization return x, y def main(): """ This function loads the data, defines the neural network architecture, trains and tests the model, and prints the results. """ # Loading the training and testing data train_x, train_y = loadDataset("../../../../datasets/mnist/mnist_train.csv", trainingSamples) test_x, test_y = loadDataset("../../../../datasets/mnist/mnist_test.csv", testingSamples) # Defining the neural network architecture model = tf.keras.models.Sequential([ tf.keras.layers.Flatten(input_shape=(784,)), # Input layer: flatten the input images tf.keras.layers.Dense(128, activation='relu'), # Hidden layer: 128 neurons, ReLU activation tf.keras.layers.Dense(10, activation='softmax') # Output layer: 10 neurons (one for each digit), softmax activation ]) # Compiling the model model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) # Training the model startTrainingTime = time.time() model.fit(train_x, train_y, epochs=10) # Training of a model by fitting training data to object endTrainingTime = time.time() trainingTime = endTrainingTime - startTrainingTime # Training time calculation # Testing the model validResults = 0 startTestingTime = time.time() predictions = model.predict(test_x) for i in range(len(test_y)): # Evaluating the results expectedResult = int(test_y[int(i)]) # Load expected result from testing dataset result = np.argmax(predictions[i]) # Calculate a result using trained model outcome = "Fail" if result == expectedResult: validResults = validResults + 1 # Counting valid results outcome = " OK " print("Nº ", i + 1, " | Expected result: ", expectedResult, " | Obtained result: ", result, " | ", outcome, " | Accuracy: ", round((validResults / (i + 1)) * 100, 2), "%") # Printing the results for each label in testing dataset endTestingTime = time.time() testingTime = endTestingTime - startTestingTime # Calculation of testing time # Printing the results print("-------------------------------") print("Results") print("-------------------------------") print("Training samples: ", trainingSamples) print("Training time: ", round(trainingTime, 2), " s") print("Testing samples: ", testingSamples) print("Testing time: ", round(testingTime, 2), " s") print("Testing accuracy: ", round((validResults / testingSamples) * 100, 2), "%") if __name__ == "__main__": main() |
Este código se encuentra disponible en nuestro repositorio de Github. Debo destacar que para que este código funcione correctamente hace falta que Tensorflow esté correctamente instalado en tu computadora. Espero escribir un post sobre ese tema en algún momento (como tantas otras cosas).
- Primero, se definen dos variables para el número de muestras de entrenamiento y pruebas.
- Luego, se define una función
loadDataset()para cargar los datos del conjunto de datos en un formato CSV. - La función
main()es la función principal del programa, donde se carga el conjunto de datos, se define el modelo, se compila el modelo, se entrena el modelo y se evalúa el modelo. - Para el modelo, se utiliza la clase
Sequential()de Keras, que es una clase que define una secuencia lineal de capas de la red neuronal. - Se definen tres capas: una capa de entrada que aplanará los datos de entrada, una capa oculta de 128 neuronas con la función de activación ReLU, y una capa de salida con 10 neuronas con la función de activación softmax.
- El modelo se compila con el optimizador «adam» y la función de pérdida «sparse_categorical_crossentropy».
- El modelo se entrena con el conjunto de datos de entrenamiento, durante 10 épocas.
- Finalmente, se evalúa el modelo en el conjunto de datos de prueba, y se imprime la precisión de las predicciones.
El resultado de ejecutar este código es el siguiente:
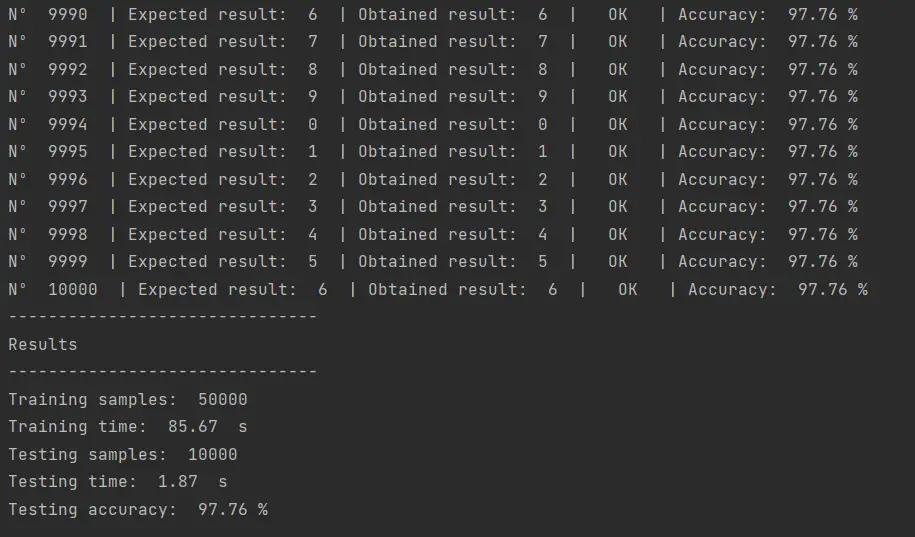
Un 97.76% de eficiencia en la clasificación, con poco más de un minuto de entrenamiento. Esto ubica a este algoritmo en el segundo lugar de los modelos que hemos probado, justo detrás del Support Vector Machine.
Al principio de la ejecución de este algoritmo veremos lo siguiente:
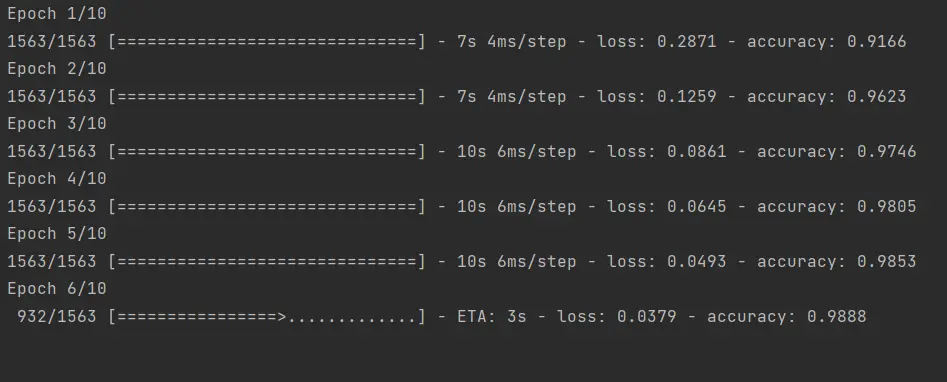
En este contexto, un epoch se refiere a una iteración completa del algoritmo de aprendizaje, donde se utiliza todo el conjunto de datos de entrenamiento una vez para actualizar los pesos de la red neuronal. En otras palabras, un epoch es cuando la red neuronal ha visto todo el conjunto de datos de entrenamiento una vez.
Durante el entrenamiento, los pesos de la red neuronal se ajustan iterativamente para minimizar el error entre las predicciones de la red y los valores reales. Cada epoch implica un ciclo completo a través del conjunto de entrenamiento y una actualización de los pesos de la red.
Normalmente, un mayor número de epochs puede mejorar la precisión del modelo, ya que la red neuronal tiene más oportunidades de aprender de los datos de entrenamiento. Sin embargo, un número excesivo de epochs puede llevar a un sobreajuste del modelo, lo que significa que el modelo se ajusta demasiado a los datos de entrenamiento y no puede generalizar bien a nuevos datos.
Para el caso de este post el propósito no es optimizar el algoritmo, sino presentar un ejemplo básico de su uso. Hay muchos hiperparámetros que podríamos modificar para mejorar la eficiencia de la clasificación, pero por ahora lo dejaremos así.
Debo mencionar que Tensorflow tiene soporte para GPU, es decir, tiene la capacidad del utilizar el hardware de la tarjeta gráfica para realizar los cálculos matemáticos correspondientes al entrenamiento del modelo. En mi caso, así luce el administrador de recursos cuando ejecuto el algoritmo en mi laptop:
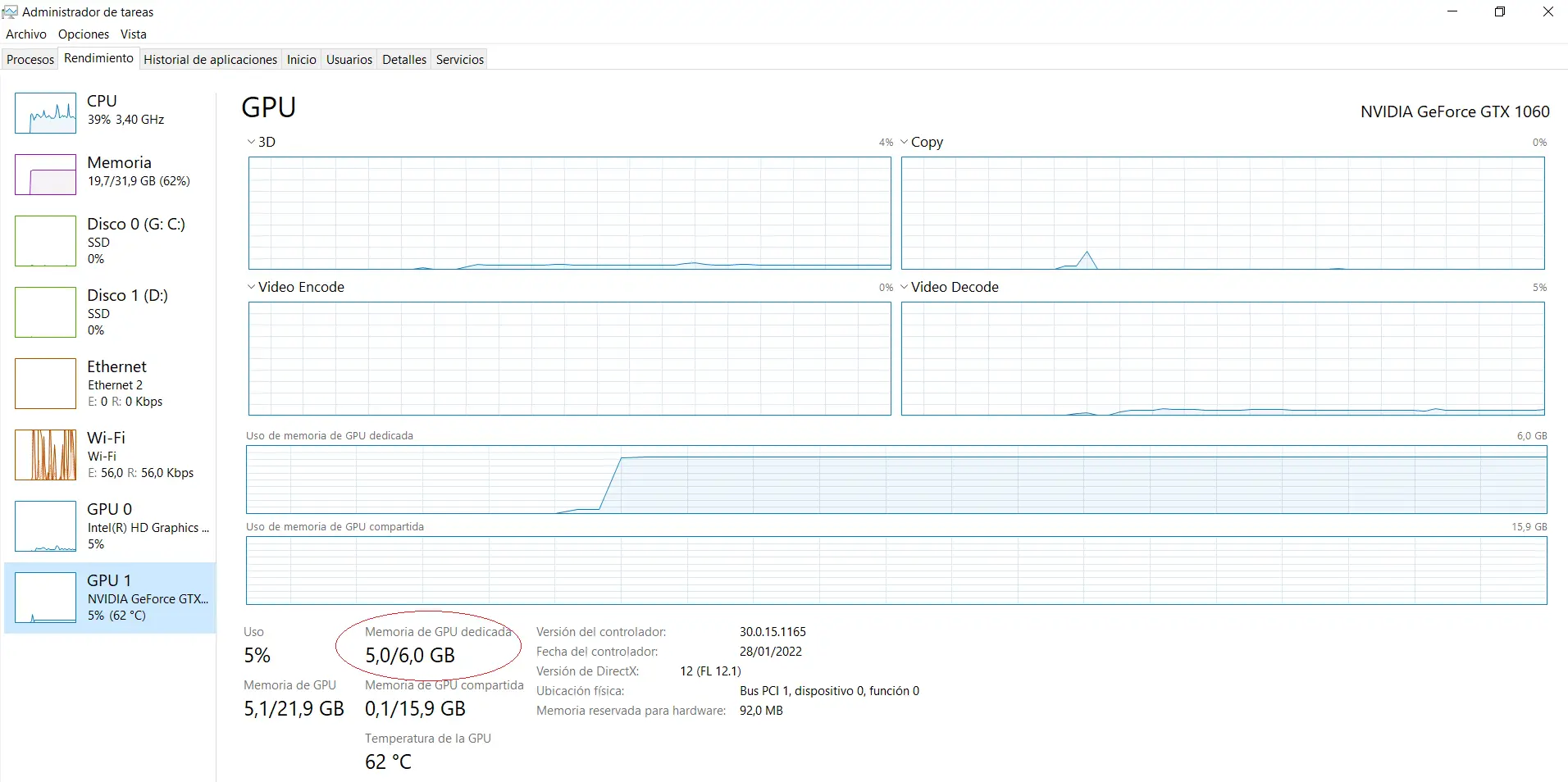
Tensorflow automáticamente utilizará el máximo de recursos disponibles, que en este caso son 5 de los 6 GB de la memoria de video. Mi hardware no es el mejor para este tema, pero me permite hacer lo mínimo que es probar ejemplos sencillos de Machine Learning.
Profundizando en los parámetros del algoritmo
En este ejemplo se utilizaron los siguientes parámetros:
optimizer='adam': el algoritmo de optimización Adam fue utilizado para actualizar los pesos de la red durante el entrenamiento. Adam es un algoritmo popular de optimización para redes neuronales que utiliza una tasa de aprendizaje adaptativa y es conocido por ser eficiente y rápido.loss='sparse_categorical_crossentropy': la función de pérdida utilizada para medir la discrepancia entre las salidas del modelo y las salidas esperadas fue la entropía cruzada categórica escasa. Esta función de pérdida es comúnmente utilizada en tareas de clasificación multiclase y es útil cuando las clases no están codificadas en one-hot encoding.metrics=['accuracy']: la métrica utilizada para evaluar el rendimiento del modelo durante el entrenamiento fue la precisión (accuracy). Esto nos da una idea de qué tan bien está clasificando el modelo durante el entrenamiento.
Además del optimizador «Adam» que se utilizó en este ejemplo, existen otros tipos de optimizadores que se pueden usar en TensorFlow para ajustar los pesos de una red neuronal durante el proceso de entrenamiento. Algunos ejemplos son:
-
Stochastic Gradient Descent (SGD): Este es uno de los optimizadores más simples y antiguos. En este método, los pesos se actualizan en pequeñas cantidades después de cada ejemplo de entrenamiento.
- Adagrad: Este optimizador ajusta la tasa de aprendizaje para cada peso según su historial de actualizaciones.
- RMSprop: Este optimizador utiliza una tasa de aprendizaje adaptativa y una media móvil exponencial de los gradientes cuadrados para escalar la tasa de aprendizaje.
- Adadelta: Este optimizador también utiliza una tasa de aprendizaje adaptativa y una media móvil exponencial de los gradientes cuadrados, pero a diferencia de RMSprop, también adapta la escala de actualización.
- Adamax: Este optimizador es una versión más escalable de Adam que utiliza el máximo de los valores absolutos de los gradientes en lugar de la media cuadrática de los gradientes.
-
Nadam: Este optimizador combina los métodos de Nesterov Accelerated Gradient (NAG) y Adam para proporcionar una mejor convergencia.
En este ejemplo, se utilizaron dos funciones de activación diferentes. La primera se utilizó en la capa oculta de la red neuronal y se llama «ReLU» (unidad lineal rectificada). ReLU es una función de activación muy popular en el aprendizaje profundo porque es fácil de calcular y a menudo proporciona mejores resultados que otras funciones de activación.
La segunda función de activación se utilizó en la capa de salida y se llama «softmax«. Softmax es una función de activación utilizada comúnmente para clasificación multiclase, ya que normaliza los valores de salida de la red neuronal para que sumen uno y se puedan interpretar como probabilidades.
El número de neuronas en la capa oculta y el número de neuronas en la capa de salida se eligen de forma empírica y pueden variar según la complejidad del problema que se esté tratando.
En este caso, la elección de 128 neuronas en la capa oculta y 10 neuronas en la capa de salida se basó en la experiencia previa en la clasificación de imágenes MNIST, ya que estos valores suelen funcionar bien en este tipo de problema.
Conclusiones
En este post se presenta un ejemplo básico de cómo configurar una red neuronal en Python utilizando la biblioteca TensorFlow para clasificar imágenes del conjunto de datos MNIST. TensorFlow es una herramienta de aprendizaje automático de código abierto desarrollada por Google que permite crear y entrenar modelos de aprendizaje automático, incluyendo redes neuronales, en una variedad de plataformas.
En el ejemplo presentado, se utilizó la clase Sequential de Keras para definir una secuencia lineal de capas de la red neuronal, con una capa de entrada que aplanó los datos de entrada, una capa oculta de 128 neuronas con la función de activación ReLU, y una capa de salida con 10 neuronas con la función de activación softmax.
Gracias por leer este post sobre cómo configurar una red neuronal en Python para la clasificación de imágenes con el MNIST dataset. Espero que haya sido útil y que hayas aprendido algo nuevo sobre Machine Learning y TensorFlow.
Si tienes alguna pregunta o comentario, no dudes en dejarlos en la sección de comentarios a continuación. Me encantaría saber tu opinión sobre el tema y responder cualquier pregunta que puedas tener.











