
Este post lo estoy publicando como una continuación de mi post anterior sobre Machine Learning en Python:
En dicho post expliqué como se construye un algoritmo que permite clasificar imágenes en Python, utilizando el paradigma de Machine Learning. El algoritmo que construí funciona sobre el MNIST dataset, sobre el cual escribí un post:
El algoritmo que construí utiliza el dataset de entrenamiento, unas 50,000 imágenes de números manuscritos, para entrenar un Support Vector Machine. Luego, con el modelo entrenado, se intenta predecir los números representados en las imágenes del dataset de pruebas (10,000 imágenes). El modelo entrenado logra predecir cerca del 98% de las imágenes, con algunos errores en imágenes que podrían considerarse ambiguas.
 Estas 3 imágenes no pudieron ser clasificadas por el algoritmo, aunque creo que es entendible el por qué del error. Aún para un ser humano, las imágenes mostradas resultan un poco confusas.
Estas 3 imágenes no pudieron ser clasificadas por el algoritmo, aunque creo que es entendible el por qué del error. Aún para un ser humano, las imágenes mostradas resultan un poco confusas.
Luego de hacer distintas pruebas con el dataset MNIST me dio curiosidad y decidí probar el modelo entrenado con números escritos por mi mismo. Es decir, se supone que si entreno un modelo de Machine Learning con números manuscritos, este debe ser funcional para números que no estén incluidos en el dataset de pruebas, ¿no?. El procedimiento que utilicé para estas pruebas y los resultados obtenidos es lo que publicaré en este post.
Construyendo mi propio dataset de pruebas
Para probar si el algoritmo es capaz de reconocer mis números necesito construir un dataset de pruebas. Para ello escribí los números del 0 al 9 en una hoja blanca y les tomé una foto con mi celular:

Luego, utilizando Photoshop, recorté los números, desaturé la imagen y eliminé el color de fondo con la herramienta de la varita mágica. Este mismo resultado se puede lograr con cualquier software que permita hacer edición de imágenes. Así me quedó la imagen:
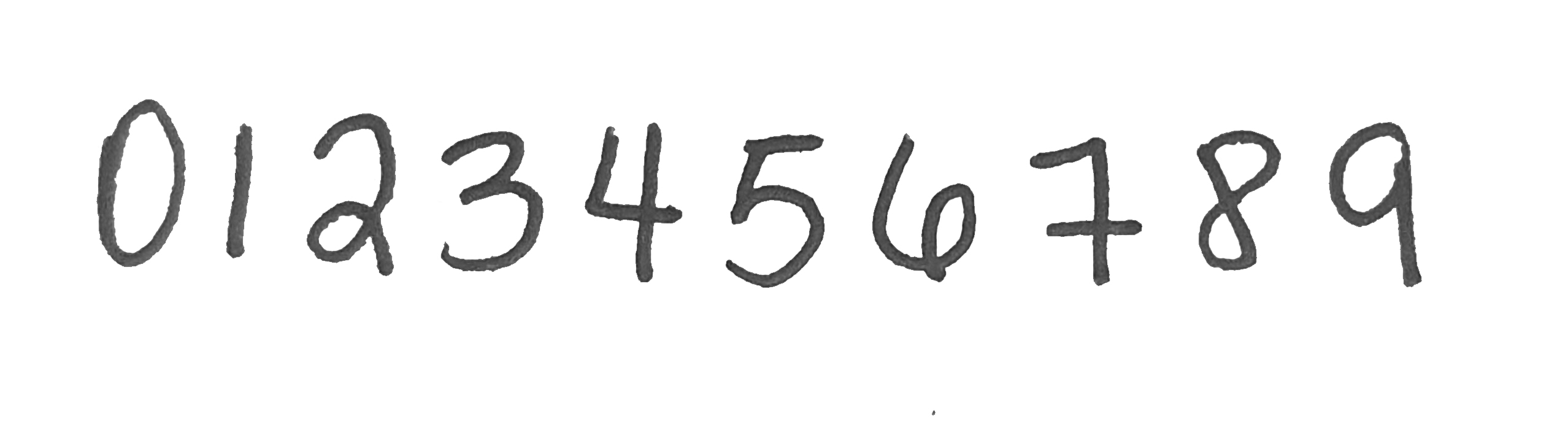
Lo siguiente que hice fue recortar cada imagen y guardarlas en formato PNG, con un tamaño de 300 x 300 pixeles. Así se ven las imágenes recortadas:

Las imágenes originales y las recortadas las he subido al repositorio de Panama Hitek en Github.
El MNIST dataset está formado por imágenes en formato 28 x 28 pixeles en escala de grises. Además las imágenes tienen fondo negro y están representadas en color blanco. El redimensionamiento e inversión de colores lo he realizado con un script en Python, el cual presentaré a continuación:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
import os from PIL import Image, ImageOps index = 0 for pictures in os.scandir("images/cropped_digits"): # Scan images in this folder original_image = Image.open(pictures.path) # Load the image rgb_image = original_image.convert("RGB") # Convert loaded image to RGB grayscale_image = ImageOps.grayscale(rgb_image) # Convert to grayscale grayscale_image = ImageOps.invert(grayscale_image) # Invert colors (black to white and vice versa) resized_image = grayscale_image.resize((28, 28)) # Resize images to the needed 28x28 format resized_image.save("images/resized_digits/" + str(index) + ".jpg") # Save transformed images to folder index = index + 1 |
Este código se encuentra disponible en Github, junto con los archivos necesarios para reproducir mis resultados. Luego de ejecutar este script, el resultado es el siguiente:
![]()
Ahora los números que escribí se han convertido en imágenes en formato 28 x 28 pixeles, con colores invertidos.
El siguiente paso es convertir estas imágenes en un conjunto de valores numéricos almacenados en un archivo CSV, de manera similar a las imágenes del dataset MNIST. Eso lo podemos lograr utilizando el siguiente script:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
import os import numpy as np from PIL import Image import pandas as pd csv_array = [] # Array to save all pixels (global array) index = 0 for pictures in os.scandir("images/resized_digits"): # Read al images in this path pixel_array = [] # Array to save all pixels from image in a row original_image = Image.open(pictures.path) # Open the image pixels = original_image.load() # Load pixels from image in a 2D array index = index + 1 for i in range(28): for j in range(28): p = int(pixels[j, i]) # Load each pixel in the 2D array pixel_array.append(p) # Append each pixel to the row array csv_array.append(pixel_array) # Append each row array to the global array csv_array = np.asarray(csv_array) # Convert array to numpy array pd.DataFrame(csv_array).to_csv("../datasets/custom/custom_mnist.csv", header=None) # Save pixels in a file |
El resultado de ejecutar este script será un archivo CSV como este:

Ahi tenemos, un archivo CSV con 10 filas y 785 columnas. Cada una de las filas es un número y las columnas son los pixeles que forman cada imagen. La primera columna representa las etiquetas de cada número.
Si utilizamos el script que publicamos en nuestro post de primeras pruebas con el MNIST dataset en Python. Utilizaré dicho script, disponible en nuestro repositorio, para convertir los pixeles del archivo CSV nuevamente en imágenes:

Estas imágenes han sido formadas a partir de mi escritura, que posteriormente fue almacenada en forma de pixeles en un archivo CSV. Como se trata de imágenes sacadas de una foto, es normal que exista algo de ruido en cada imagen:
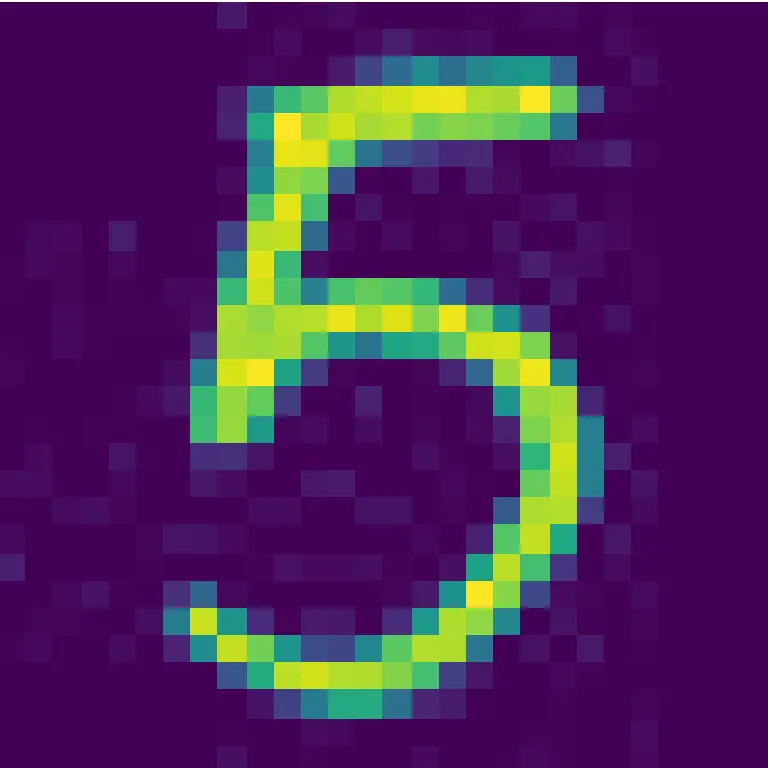
Le agregaré una condición al script que convierte las imágenes en pixeles y las almacena en un archivo CSV. Si el valor de un pixel es menor a 50, que se considere un cero. El script está disponible en este enlace y produce este resultado:
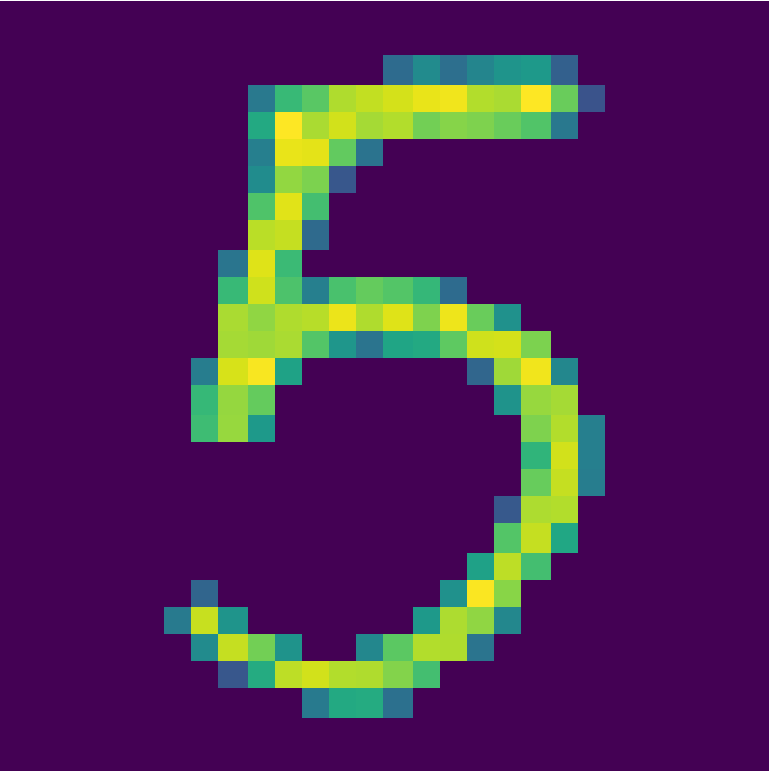
Vemos que ahora tenemos una imagen más limpia, si la comparamos a la anterior. Ha sido un filtrado sencillo que nos permite eliminar información inútil para nuestros propósitos.
Identificando los números en Python
Ahora que tenemos las imágenes ajustadas en un dataset, vamos a proceder a probar el algoritmo con mis números.
El código que utilizaré es el siguiente (disponible en Github):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 |
import pandas as pd import numpy as np import time as time from sklearn import svm trainingSamples = 50000 # Self explanatory testingSamples = 10 """ Here I set the global variables, which will be used to test the computing time for both training and testing """ startTrainingTime = 0 endTrainingTime = 0 trainingTime = 0 startTestingTime = 0 endTestingTime = 0 testingTime = 0 def loadDataset(fileName, samples): # A function for loading the data from a dataset x = [] # Array for data inputs y = [] # Array for labels (expected outputs) train_data = pd.read_csv(fileName, header=None) # Data has to be stored in a CSV file, separated by commas y = np.array(train_data.iloc[0:samples, 0]) # Labels column x = np.array(train_data.iloc[0:samples, 1:]) / 255 # Division by 255 is used for data normalization return x, y def main(): train_x, train_y = loadDataset("../datasets/mnist/mnist_train.csv", trainingSamples) # Loading training data test_x, test_y = loadDataset("../datasets/custom/custom_mnist.csv", testingSamples) # Loading testing data clf = svm.SVC() # Classifier object startTrainingTime = time.time() clf.fit(train_x, train_y) # Training of a model by fitting training data to object endTrainingTime = time.time() trainingTime = endTrainingTime - startTrainingTime # Training time calculation validResults = 0 startTestingTime = time.time() for i in range(len(test_y)): # A for loop to evaluate result vs expected results expectedResult = int(test_y[int(i)]) # Load expected result from testing dataset result = int(clf.predict(test_x[int(i)].reshape(1, len(test_x[int(i)])))) # Calculate a result outcome = "Fail" if result == expectedResult: validResults = validResults + 1 # Counting valid results outcome = " OK " print("Nº ", i + 1, " | Expected result: ", expectedResult, " | Obtained result: ", result, " | ", outcome, " | Accuracy: ", round((validResults / (i + 1)) * 100, 2), "%") # Printing the results for each label in testing dataset endTestingTime = time.time() testingTime = endTestingTime - startTestingTime # Calculation of testing time print("-------------------------------") print("Results") print("-------------------------------") print("Training samples: ", trainingSamples) print("Training time: ", round(trainingTime, 2), " s") print("Testing samples: ", testingSamples) print("Testing time: ", round(testingTime, 2), " s") print("Testing accuracy: ", round((validResults / testingSamples) * 100, 2), "%") if __name__ == "__main__": main() |
Este código está basado en el que publiqué en mi post anterior, ¿Cómo construir un clasificador de imágenes con Machine Learning en Python?. Le he hecho algunas modificaciones para que utilice mi dataset en vez del dataset de pruebas de MNIST.
La primera prueba que haré será entrenar mi modelo con 1000 imágenes, para ver si logra reconocer mis números manuscritos:
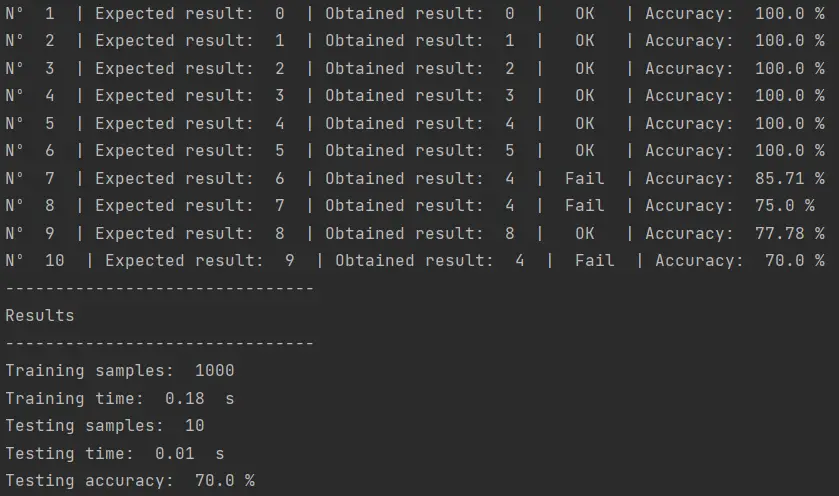
Como vemos, al utilizar 1000 muestras de entrenamiento se logra detectar el 7 de los 10 números que escribí. El algoritmo falló en detectar el 6, 7 y 9, confundiéndolos con el número 4.
Trataré de mejorar el performance del algoritmo aumentando la cantidad de muestras utilizadas en el entrenamiento, esta vez con 5000:
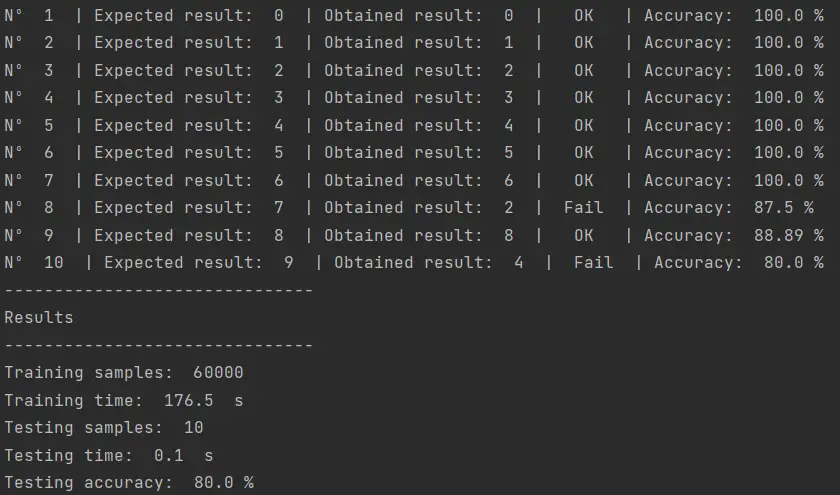
Ahora el algoritmo logra reconocer 8 de las 10 imágenes. El 7 y el 9 siguen siendo un problema. Aumentaré el dataset de entrenamiento hasta el valor máximo de 60,000 para ver si logramos reconocer todos los números:
No mejoró. Parece que tenemos un problema con el 7 y el 9. También lo intenté utilizando un kernel polinomial de grado 2 y grado 3, los cuales mostraron un performance en mi post anterior sobre este tema. El resultado no mejoró.
¿Cuál será la razón por la cual no está funcionando el algoritmo? Para responder esto hace falta revisar las imágenes del dataset de pruebas. Escribí un script que me permite visualizar 100 imágenes del set de pruebas para ver si tienen alguna diferencia con respecto a los números que escribí. El primer número que visualizaré será el 7:

Las imágenes encerradas en rojo son números 7 con una línea horizontal, similar a la forma como yo escribo el 7:

Yo creo que el problema está en que solamente 9 de las primeras 100 imágenes con el número 7 tienen una línea horizontal. Eso es un 9%, un porcentaje que no sabemos si se mantiene en el resto del dataset.
Es probable que el algoritmo que entrenamos es más sensible a los números 7 sin la línea horizontal en el medio. Es lo único que se me ocurre, pues no creo que el 7 que escribí sea especialmente difícil de interpretar.
En el caso del 9, así se ven las primeros 100 imágenes con el número 9 en el dataset de entrenamiento:

Esta vez las diferencias entre las imágenes con un 9 en el dataset no lucen tan distintas al 9 que escribí:

No estoy seguro cual es la diferencia. Talvez la inclinación, que en el caso de mi número está inclinado hacia la derecha y en el dataset la mayoría están inclinados hacia la izquierda. O talvez sea el grosor de la línea o la intensidad de la misma.
Podemos hacer una prueba aumentando el grosor de las líneas, agregando una condición al script que convierte las imágenes en pixeles. Le podemos decir que si un pixel tiene un valor superior a 50 (en la escala de 0 a 255), que lo convierta en un pixel blanco (255). El resultado se vería así:

Vamos a ver como le va al algoritmo de clasificación con estas nuevas imágenes:
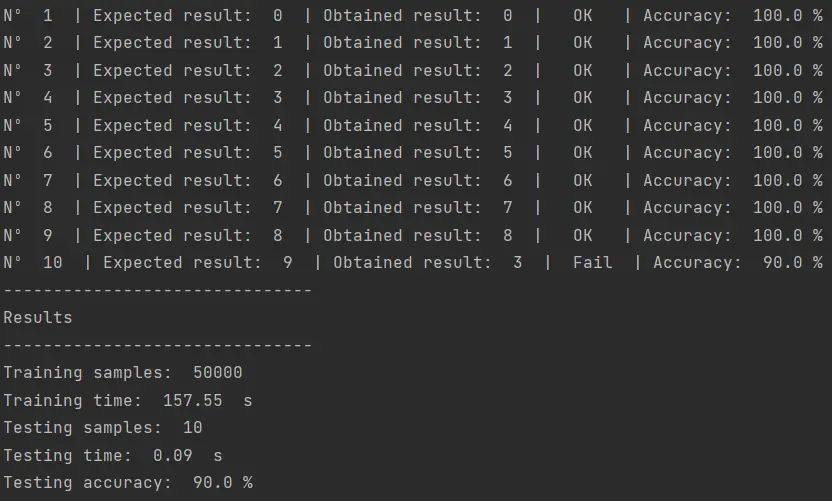
Esto es… más que interesante. Hemos resuelto el problema del número 7, el cual parecía más difícil de resolver. El 9 sigue siendo un problema y, además, la confusión ahora es con el número 3. Esto nos demuestra que a veces es necesario aplicar un preprocesamiento de datos antes de aplicar los algoritmos de Machine Learning para lograr mejores resultados.
Esta prueba fue con el kernel RBF. Y si probamos con el kernel polinomial?
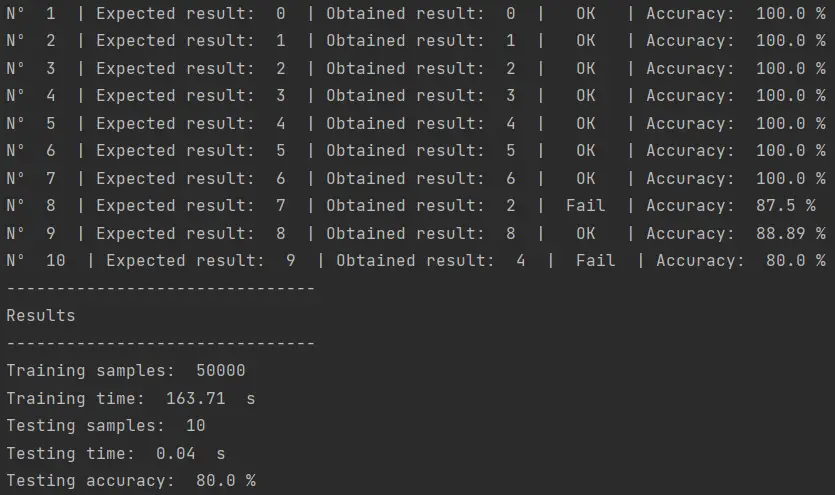
Pues no, parece que el kernel polinomial cúbico no es la solución. Y tampoco lo fue el cuadrático. Parece que tendremos que hacer un análisis más profundo para ver cual de todos los algoritmos disponibles podemos utilizar para reconocer mi propia escritura.
Por lo pronto esto es todo lo que compartiré en este post. En publicaciones futuras espero retomar este tema con otros algoritmos sobre los que estaré escribiendo. Espero que la información aquí publicada sea de utilidad para ustedes.
UPDATE: Luego de probar múltiples algoritmos de clasificación, con una red neuronal convolucional logramos identificar correctamente todos los números.




")









