
Este post será un preámbulo a mis publicaciones sobre algoritmos de Machine Learning en Python, en los cuales el uso de archivos CSV es muy común.
Cuando se trabaja en Machine Learning se suelen utilizar archivos CSV en los que se almacena información para el entrenamiento y la evaluación de los modelos de inteligencia artificial. Es por ello que cualquier aprendizaje en el tema de Machine Learning inicia, según mi criterio, con la importación de archivos CSV en Python.
Esto, en realidad, no es tan complicado. Para esta demostración he creado un proyecto en Pycharm (véase Pycharm, un IDE para programar en Pyton) en el que he agregado un archivo llamado main.py. También he agregado un archivo llamado train.csv para la prueba de concepto. Este archivo lo pueden descargar utilizando este enlace.
Hecho esto, podemos empezar a programar. Empezaré probando el siguiente código:
|
1 2 3 |
import pandas as pd train_data = pd.read_csv("train.csv") |
Este código permite importar la librería (en realidad es biblioteca, pero en español nos gusta decirlo mal) «pandas», la cual se especializa en el manejo de archivos CSV. Se crea una variable llamada train_data (una matriz) a la cual se le asigna el contenido del archivo train.csv.
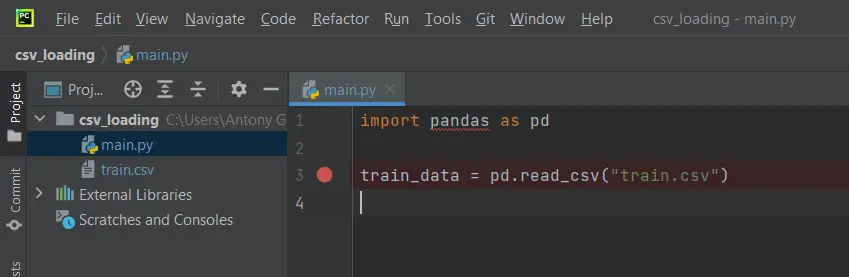
Nótese que aparece una línea roja debajo de la palabra pandas. Esto se debe a que la librería no está instalada, lo cual se puede resolver fácilmente. Colocamos el puntero del mouse encima de la librería que nos hace falta y nos debe aparecer un menú con el que podemos importar pandas:
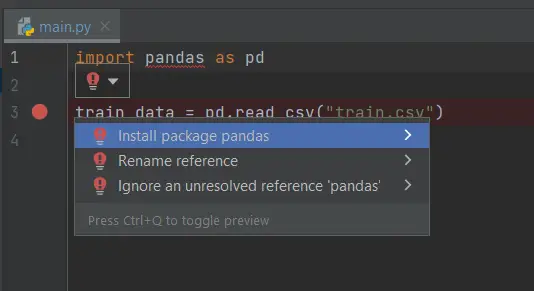
A veces esto no funciona y nos toca ir al gestor de repositorios de Pycharm, el cual se ubica en el menú File>Settings>Project>Python Interpreter.
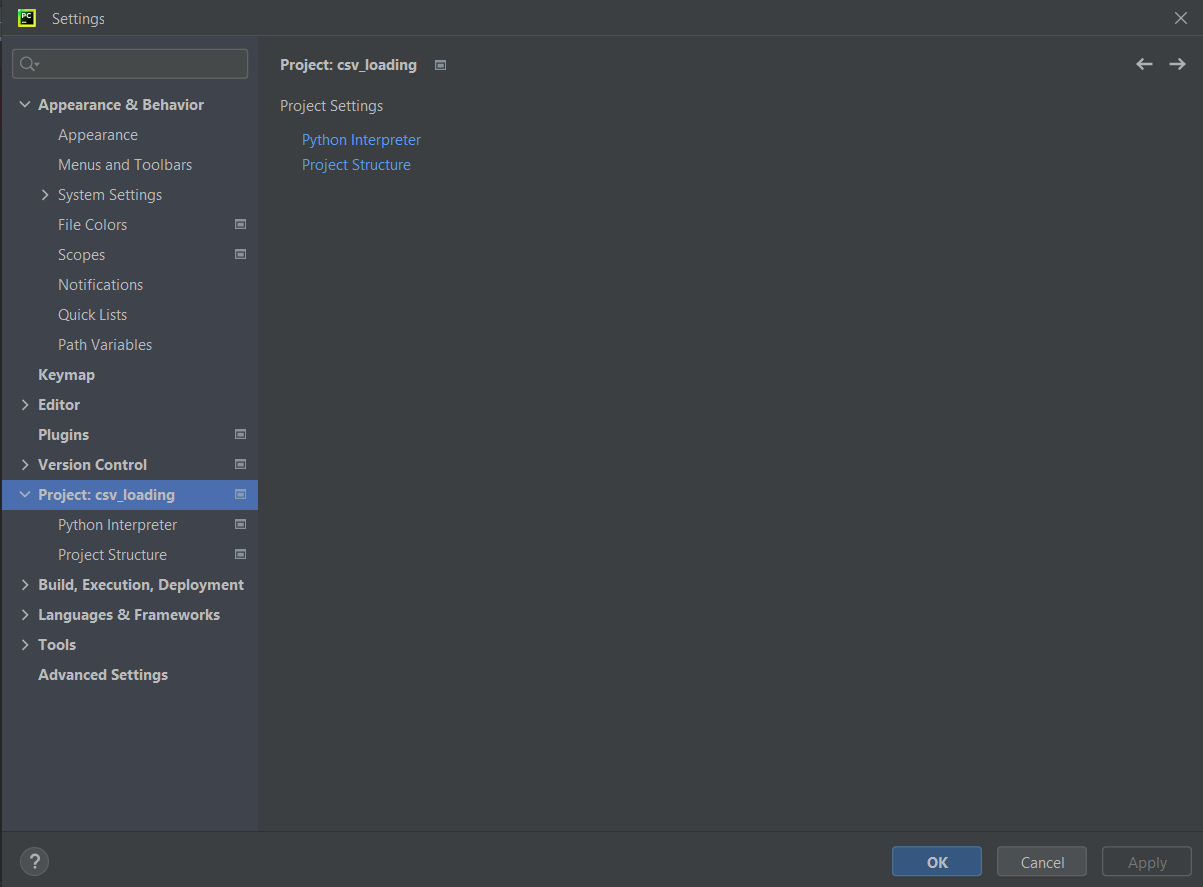
Al precionar el botón «+» se puede instalar cualquier recurso que nos haga falta.
Volviendo al código con el que empezamos, ahora debemos poder ejecutar el código sin problemas. Sin embargo, este no hará la gran cosa. Estamos cargando el archivo CSV, pero no hacemos nada con eso.
Agregaremos las siguientes instrucciones:
|
1 2 3 4 |
import pandas as pd train_data = pd.read_csv("train.csv") print(train_data) |
Esto produce el siguiente resultado:
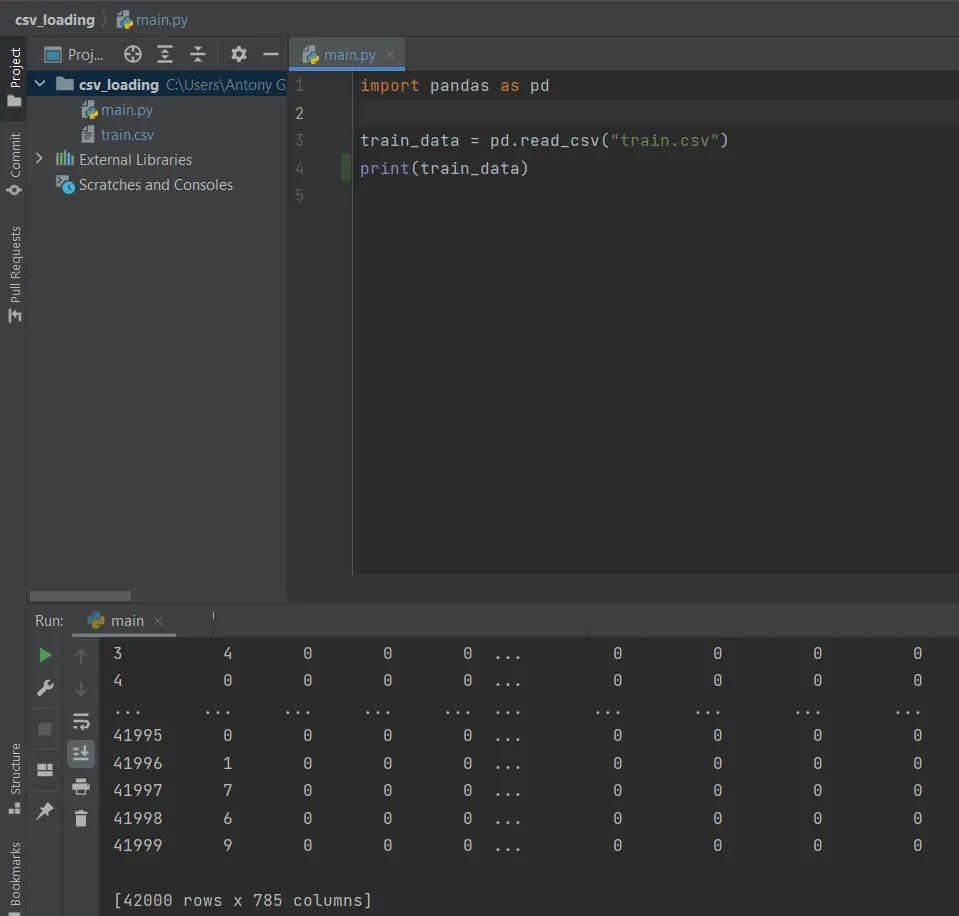
Como vemos, en la parte de abajo se imprime el contenido del archivo CSV en un formato comprimido. Y ya está. Hemos cargado un archivo CSV en Python y lo hemos almacenado en una matriz.
Ahora lo que haremos será hacer algunas operaciones con la matriz que hemos cargado, pues para trabajar en Machine Learning hace falta separar los datos en matrices con datos de entrada y de salida. Para entender esto necesitamos comprender lo que es un dataset y su composición.
El dataset que he utilizado como para probar este código (archivo train.csv) es el MNIST, un dataset muy popular en Machine Learning. MNIST está formado por 60,000 imágenes en formato 28×28 pixeles, las cuales contienen números manuscritos.

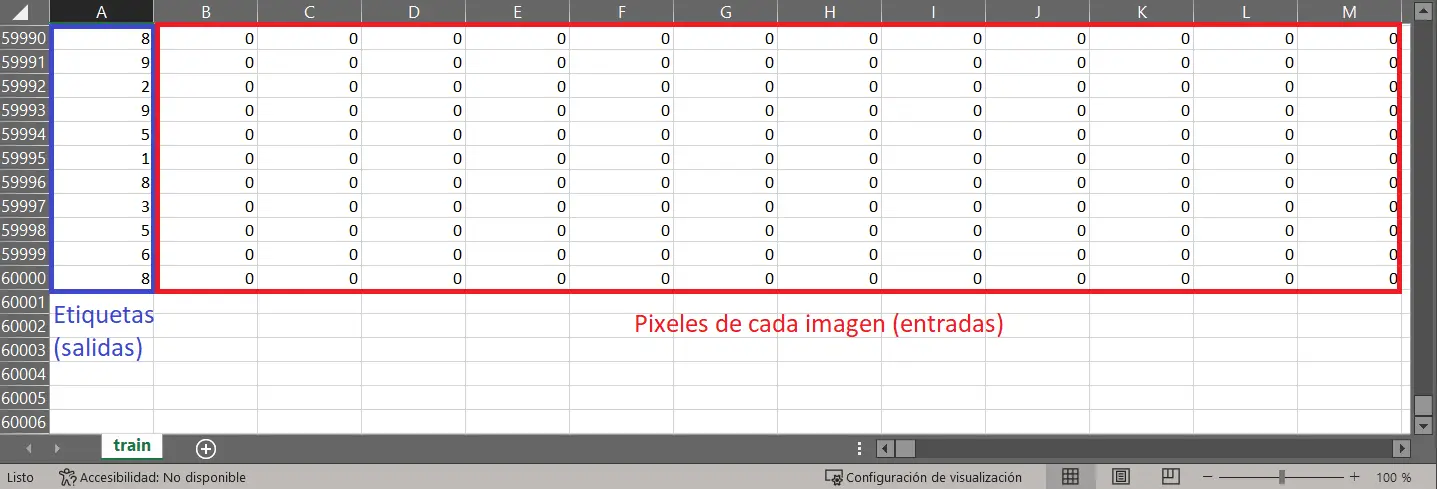
Estos números se encuentran almacenados en el archivo CSV como una única fila de valores entre 0 y 255, donde 0 representa un pixel negro y 255 representa un pixel totalmente blanco.
En la hoja de datos la priemera columna representa el valor de la etiqueta, mientras que el resto de las columnas representa los pixeles de cada imagen:
Una de las formas más comunes de trabajar con Machine Learning es:
- Diseñar un modelo
- Entrenarlo con datos de entrenamiento
- Probar el modelo diseñado
El MNIST dataset cuenta con un set de entrenamiento y con otro de pruebas (no incluido en este post). Cuando se entrena un modelo de Machine Learning se necesita proporcionar datos de entrada y los datos que se espera obtener en la salida del modelo. Es por esta razón que para usar el MNIST dataset hace falta separar la columna azul (ver imagen anterior) del resto de las columnas (en color rojo).
Esto lo podemos lograr de la siguiente manera:
|
1 2 3 4 5 6 7 8 |
import pandas as pd x=[] y=[] train_data = pd.read_csv("train.csv") x=train_data.iloc[:, 0] y = train_data.iloc[:, 1:] print(x.shape) print(y.shape) |
El resultado obtenido al ejecutar este código debe ser:
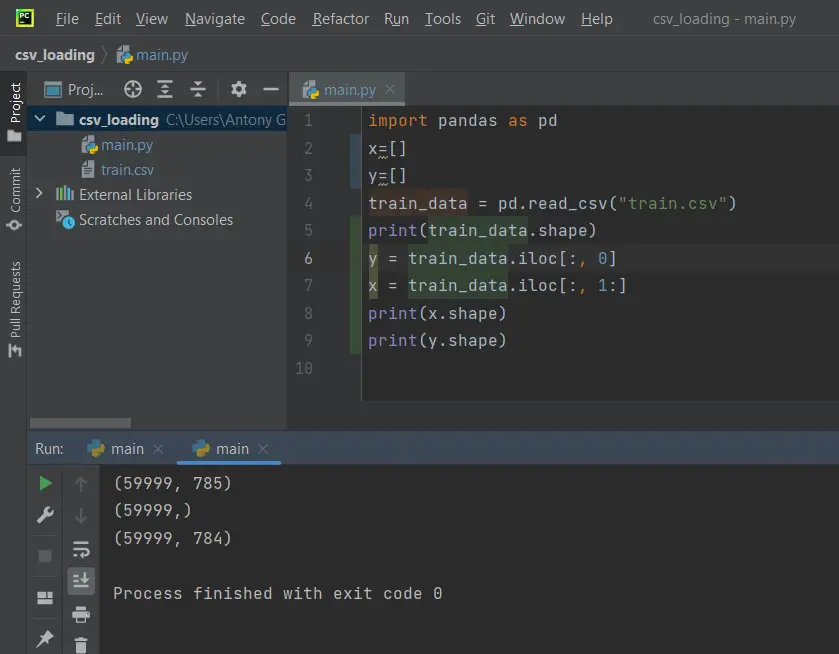
De esta forma hemos separado la matriz con el dataset en dos submatrices, «x» y «y«. La matriz x cuenta con los datos de entrada y la matriz y almacena los datos de salida, o etiquetas del dataset.
Otra operación importante con los datasets es la reducción del tamaño del dataset. No siempre vamos a necesitar los 60,000 datos almacenados en el archivo CSV. Para facilitar la reutilización del código que estoy mostrando aquí he decidido crear una función llamada loadData(), la cual tiene como parámetros el nombre del dataset y la cantidad de muestras que se desea utilizar.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
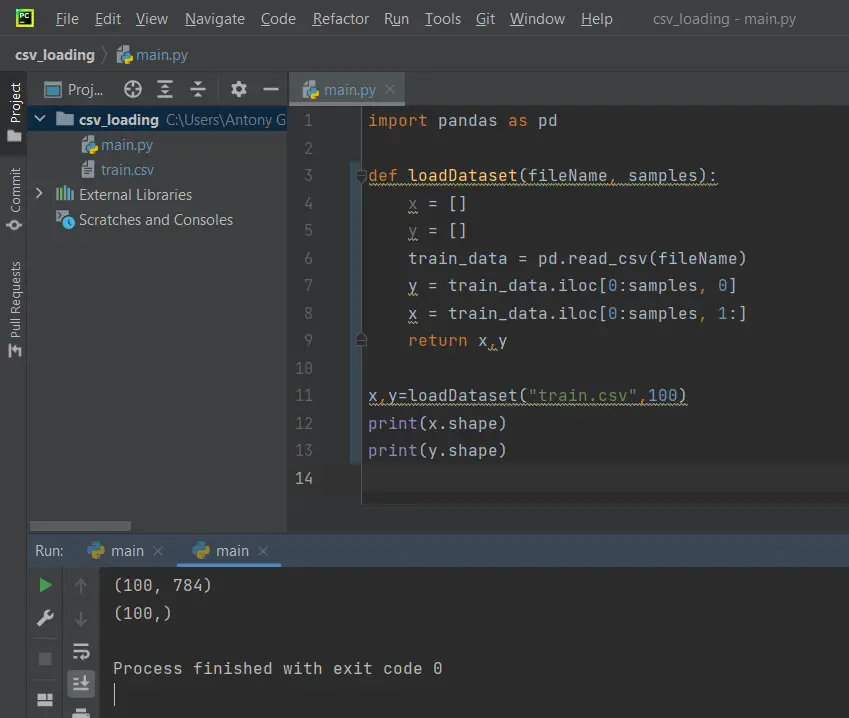
import pandas as pd def loadDataset(fileName, samples): x = [] y = [] train_data = pd.read_csv(fileName) y = train_data.iloc[0:samples, 0] x = train_data.iloc[0:samples, 1:] return x,y x,y=loadDataset("train.csv",100) print(x.shape) print(y.shape) |
Este debe ser el resultado:
Ahora podemos sar esta función cada vez que necesitemos cargar un dataset o, por lo menos, el MNIST. Para utilizar este código con otros datasets éstos deben tener una estructura similar al MNIST, es decir, con las etiquetas ubicadas en la primera columna.
El código final de este post puede descargarse desde nuestro repositorio de Github. En futuras publicaciones espero empezar a probar modelos de Machine Learning, para los cuales utilizaré lo aquí expuesto como referencia.















