
En el post de hoy exploraremos una variedad de clasificadores y su rendimiento con el dataset MNIST. Si no está familiarizado con el conjunto de datos MNIST, es una colección de 70.000 pequeñas imágenes de dígitos escritos a mano, que se utiliza comúnmente como una referencia para probar algoritmos de Machine Learning. Si quieres saber más sobre este dataset te invitamos a revisar nuestra publicación sobre este tema.
Para esta publicación utilizaremos un script para entrenar y evaluar varios clasificadores diferentes en el conjunto de datos MNIST, incluyendo AdaBoost, Random Forest, K-Nearest Neighbors y otros. Mediremos los tiempos de entrenamiento y prueba de cada clasificador, así como su precisión en el conjunto de prueba. Al final de este post, tendrás una mejor comprensión de cómo diferentes clasificadores funcionan en el conjunto de datos MNIST y cómo elegir el mejor clasificador que mejor se adapte a tus necesidades.
Clasificadores en Machine Learning
En Machine Learning, los clasificadores son una herramienta fundamental para resolver problemas de clasificación. Básicamente existen dos tipos de algoritmos: los de aprendizaje supervisado y los aprendizaje no supervisado.
En el aprendizaje supervisado, se proporciona al modelo tanto datos como etiquetas, y se espera que el modelo sea capaz de predecir las etiquetas para nuevos datos. Los clasificadores son un tipo de modelo de aprendizaje supervisado que se utilizan para asignar a una observación dada a una de varias categorías o clases. En este post estaremos revisando clasificadores de aprendizaje supervisado.
Existen diferentes tipos de clasificadores:
-
Clasificadores lineales
Estos clasificadores se entrenan utilizando un límite de decisión lineal, lo que significa que tratan de separar los datos en diferentes clases encontrando una combinación lineal de las características que separa máximamente las diferentes clases. Estos clasificadores pueden ser útiles cuando el límite de decisión entre las clases es aproximadamente lineal, pero pueden no ser tan efectivos cuando el límite es más complejo.
Entre los clasificadores lineales podemos mencionar el Logistic Regression, Perceptron, RidgeClassifier, SGDClassifier, LinearSVC y NearestCentroid.
-
Árboles de decisión
Los clasificadores de árbol de decisión funcionan creando un modelo en forma de árbol de decisiones basado en las características de los datos. El modelo se entrena dividiendo recursivamente los datos en conjuntos más pequeños y más pequeños en base a una prueba de valor de característica. La partición final de los datos resulta en las hojas del árbol, que contienen las etiquetas de clase predichas. Los árboles de decisión son simples de entender e interpretar, pero pueden ser propensos al sobreajuste si el árbol se vuelve demasiado complejo.
Entre los clasificadores tipo decision-tree tenemos: DecisionTreeClassifier y ExtraTreeClassifier.
-
Clasificadores de ensamblado
Son un tipo de clasificador que combina las predicciones de múltiples clasificadores base para mejorar la precisión general del modelo. Los métodos de ensamblado funcionan en el principio de que las predicciones combinadas de múltiples modelos a menudo son más precisas que las predicciones de cualquier modelo individual. Hay varias técnicas diferentes para combinar las predicciones de clasificadores base, como boosting, bagging y bootstrapping. Los clasificadores de ensamblado se utilizan ampliamente en la práctica debido a su capacidad para mejorar el rendimiento de los clasificadores base y manejar patrones complejos en los datos.
Entre los clasificadores de ensamblado tenemos: AdaBoostClassifier, BaggingClassifier, GradientBoostingClassifier y RandomForestClassifier.
-
Support Vector Machines
Las Máquinas de Vectores de Soporte (SVMs, por sus siglas en inglés) son un tipo de clasificador lineal que encuentra el hiperplano en el espacio de características que separa máximamente las diferentes clases. El hiperplano se elige de tal manera que la distancia desde él hasta los ejemplos más cercanos de cada clase se maximiza, lo que se conoce como margen. Los ejemplos que están más cerca del hiperplano y se utilizan para determinar su posición se conocen como vectores de soporte.
Las SVMs se pueden ampliar para manejar la clasificación no lineal utilizando el «kernel trick», que mapea los datos de entrada en un espacio de características de mayor dimensión donde se puede encontrar un límite de decisión lineal. Las SVMs son conocidas por su buen rendimiento y capacidad para manejar datos de alta dimensionalidad, pero pueden ser sensibles al ajuste de hiperparámetros y pueden ser lentas al entrenar en grandes conjuntos de datos.
Entre los clasificadores tipo Support Vector Machine tenemos: LinearSVC, NuSVC, SVC.
-
Neighbor classifiers
Los neighbor classifiers son un tipo de clasificador basado en instancias que almacena los ejemplos de entrenamiento y predice la clase de un ejemplo de prueba encontrando los ejemplos almacenados que son más similares a él, basándose en una medida de distancia como la distancia Euclidiana. La predicción final se realiza agregando las etiquetas de clase de los ejemplos más similares, como tomando el voto mayoritario o la media.
Los neighbor classifiers son simples y fáciles de implementar, pero pueden ser lentos para clasificar nuevos ejemplos y requieren una gran cantidad de memoria para almacenar los ejemplos de entrenamiento. A menudo se utilizan como método base para comparar con clasificadores más complejos y pueden ser efectivos cuando el límite de decisión entre las clases es suave y continuo.
Entre los clasificadores tipo neighbor classifiers tenemos: KNeighborsClassifier, NearestCentroid, RadiusNeighborsClassifier.
-
Clasificadores naive Bayes
Los clasificadores naive Bayes son un tipo de clasificador probabilístico que utiliza el teorema de Bayes para predecir la clase de un ejemplo de prueba basándose en la probabilidad de que el ejemplo pertenezca a cada clase, dado las características del ejemplo. El teorema de Bayes establece que la probabilidad de un evento (la clase del ejemplo de prueba) se puede calcular basándose en la probabilidad de que el evento ocurra dado la evidencia (las características del ejemplo de prueba) y la probabilidad previa del evento ocurriendo (la frecuencia de la clase en el conjunto de entrenamiento).
La suposición de los clasificadores naive Bayes es que las características del ejemplo son independientes entre sí, lo que significa que la probabilidad de cada característica no se ve afectada por la presencia o ausencia de otras características. Esta suposición a menudo no es cierta en los datos del mundo real, pero los clasificadores naive Bayes aún son efectivos en muchos casos y se conocen por su simplicidad y tiempos rápidos de entrenamiento y predicción.
Entre los clasificadores naive Bayes tenemos: BernoulliNB, ComplementNB, GaussianNB, MultinomialNB.
Cabe destacar que estos no son los únicos algoritmos de Machine Learning disponibles en la actualidad. Existen muchos otros clasificadores disponibles en otras librerías y frameworks de Machine Learning. Algunos ejemplos incluyen XGBoost y LightGBM en la librería XGBoost, Redes Neuronales en las librerías TensorFlow y PyTorch, y Naive Bayes en la librería Orange, entre otras.
Cada uno de estos clasificadores tiene sus propias ventajas y desventajas y puede ser más o menos efectivo dependiendo del problema y del conjunto de datos en cuestión. Es importante evaluar diferentes opciones y realizar pruebas para determinar cuál es el mejor clasificador para un problema dado.
Evaluación de múltiples clasificadores
A continuación les presentaré un script en Python en el que vamos a probar múltiples algoritmos de clasificación sobre el dataset MNIST. Para cada clasificador mediremos el tiempo de entrenamiento, tiempo de prueba y la precisión con la que logran clasificar las muestras de prueba.
El script es el siguiente:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
from sklearn.ensemble import AdaBoostClassifier, BaggingClassifier, GradientBoostingClassifier, RandomForestClassifier from sklearn.linear_model import LogisticRegression, Perceptron, RidgeClassifier, SGDClassifier from sklearn.naive_bayes import BernoulliNB, ComplementNB, GaussianNB, MultinomialNB from sklearn.neighbors import KNeighborsClassifier, NearestCentroid, RadiusNeighborsClassifier from sklearn.svm import LinearSVC, NuSVC, SVC from sklearn.tree import DecisionTreeClassifier, ExtraTreeClassifier import pandas as pd import numpy as np import time as time def loadDataset(fileName, samples): # A function for loading the data from a dataset x = [] # Array for data inputs y = [] # Array for labels (expected outputs) train_data = pd.read_csv(fileName) # Data has to be stored in a CSV file, separated by commas y = np.array(train_data.iloc[0:samples, 0]) # Labels column x = np.array(train_data.iloc[0:samples, 1:]) / 255 # Division by 255 is used for data normalization return x, y train_x,train_y = loadDataset("../../../../datasets/mnist/mnist_train.csv",50000) test_x,test_y = loadDataset("../../../../datasets/mnist/mnist_test.csv",10000) # Create a dictionary to store the training accuracy of each classifier accuracies = {} # Create a list of classifiers classifiers = [ AdaBoostClassifier(), BaggingClassifier(), BernoulliNB(), ComplementNB(), DecisionTreeClassifier(), ExtraTreeClassifier(), GradientBoostingClassifier(), KNeighborsClassifier(), MultinomialNB(), NearestCentroid(), NuSVC(), Perceptron(), RandomForestClassifier(), RidgeClassifier(), SGDClassifier(), SVC() ] # Iterate over the classifiers and fit each one to the training data for clf in classifiers: start = time.time() clf.fit(train_x, train_y) end = time.time() trainingTime = end - start start = time.time() accuracy = clf.score(test_x, test_y) end = time.time() testingTime = end - start accuracies[clf.__class__.__name__] = accuracy print(f"{clf.__class__.__name__} | training time: {trainingTime:.2f} seconds, testing time: {testingTime:.2f} seconds, {accuracy * 100:.2f}%") # Find the classifier with the highest accuracy best_classifier = max(accuracies, key=accuracies.get) print("-----------------------------------") print(f"Best classifier: {best_classifier}") |
Este script lo pueden descargar directamente desde nuestro repositorio de Github. El resultado de ejecutar el script es el siguiente:
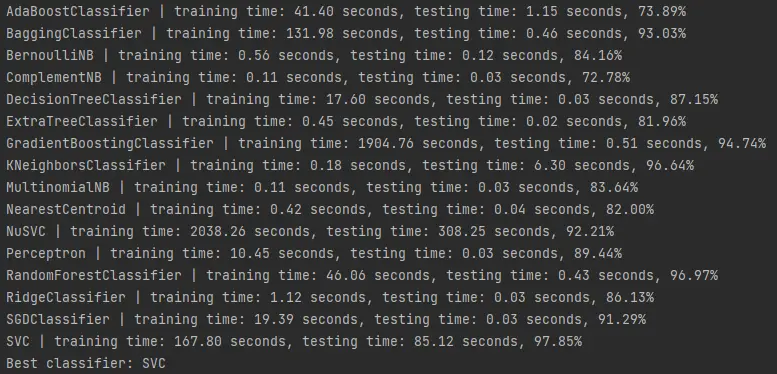
Aquí los resultados en formato de texto:
AdaBoostClassifier | training time: 41.40 seconds, testing time: 1.15 seconds, 73.89%
BaggingClassifier | training time: 131.98 seconds, testing time: 0.46 seconds, 93.03%
BernoulliNB | training time: 0.56 seconds, testing time: 0.12 seconds, 84.16%
ComplementNB | training time: 0.11 seconds, testing time: 0.03 seconds, 72.78%
DecisionTreeClassifier | training time: 17.60 seconds, testing time: 0.03 seconds, 87.15%
ExtraTreeClassifier | training time: 0.45 seconds, testing time: 0.02 seconds, 81.96%
GradientBoostingClassifier | training time: 1904.76 seconds, testing time: 0.51 seconds, 94.74%
KNeighborsClassifier | training time: 0.18 seconds, testing time: 6.30 seconds, 96.64%
MultinomialNB | training time: 0.11 seconds, testing time: 0.03 seconds, 83.64%
NearestCentroid | training time: 0.42 seconds, testing time: 0.04 seconds, 82.00%
NuSVC | training time: 2038.26 seconds, testing time: 308.25 seconds, 92.21%
Perceptron | training time: 10.45 seconds, testing time: 0.03 seconds, 89.44%
RandomForestClassifier | training time: 46.06 seconds, testing time: 0.43 seconds, 96.97%
RidgeClassifier | training time: 1.12 seconds, testing time: 0.03 seconds, 86.13%
SGDClassifier | training time: 19.39 seconds, testing time: 0.03 seconds, 91.29%
SVC | training time: 167.80 seconds, testing time: 85.12 seconds, 97.85%
Parece que el clasificador con los mejores resultados es el SVC, un Support Vector Machine. Cabe destacar que estos clasificadores fueron utilizados con los parámetros por default. Probablemente es posible mejorar la eficiencia de todos y cada uno de los algoritmos haciendo un poco de hyperparameter tunning. Sobre ese tema ya hemos hablado en publicaciones anteriores sobre el tema de Machine Learning.
Nótese que aunque el SVC logra una mejor precisión, su tiempo de entrenamiento (167.8 segundos) es relativamente alto en comparación a otros algoritmos con eficiencia similares, como el clasificador Random Forest (46.06) y KNeighborsClassifier (0.18). Este último ha llamado mucho mi atención por lo rápido que ejecuta el entrenamiento y los excelentes resultados que obtiene. Creo que haré un post revisando este clasificador tal como ya lo hice con el Random Forest.
Otros algoritmos como el GradientBoostingClassifier (1904 segundos) y el NuSVC (2038 segundos) tardan una eternidad en entrenarse, con resultados pobres en comparación a otros algoritmos mucho más rápidos.
Conclusiones
En conclusión, hemos visto cómo diferentes clasificadores pueden ser entrenados y evaluados en el conjunto de datos MNIST. Hemos encontrado que la precisión y el tiempo de entrenamiento y prueba varían entre los diferentes clasificadores, y que el mejor clasificador para un conjunto de datos específico dependerá del conjunto de datos y el tipo de datos en cuestión. Los resultados mostrados son válidos para el conjunto de datos MNIST, pero podrían no serlo para otras tareas de clasificación.
Espero que hayas disfrutado de este post y hayas aprendido algo sobre cómo elegir y evaluar clasificadores en Machine Learning. Si tienes alguna pregunta o comentario, no dudes en dejármelo a continuación. ¡Gracias por leer!











