
En este post, te mostraré cómo entrenar un modelo de Machine Learning en Python utilizando Sklearn y cómo exportarlo como código ejecutable en Java.
Es importante destacar que la mayoría de los recursos de Machine Learning están disponibles en Python, como por ejemplo Sklearn. En contraste, aunque existen recursos para construir algoritmos de Machine Learning en Java, no son tan sencillos de utilizar como en Python y cuentan con menos documentación.
Recientemente, he descubierto que es posible construir y entrenar un modelo de clasificación en Sklearn en Python, y convertir el modelo entrenado en una clase que puede ser utilizada en Java para replicar los resultados obtenidos en Python de manera nativa en Java. Este enfoque te permitirá aprovechar las fortalezas de ambos lenguajes y utilizarlos de manera efectiva en tu proyecto de Machine Learning.
Antes de entrar en materia les recomiendo revisar estas dos publicaciones previas, pues me basaré en ellas para desarrollar el modelo que presentaré en este post:
- Convertir modelo de Machine Learning en código ejecutable en Python
- Análisis de datos mamografías con Machine Learning
Sin más que decir, empecemos.
Construcción del modelo en Python
Para esta demostración utilizaremos el modelo de LogisticRegression que presentamos en nuestra publicación anterior. Este modelo permite hacer predicciones sobre los resultados de biopsias con los resultados de las mamografías y la evaluación BI-RADS. Es un modelo sencillo, con apenas 5 features y dos posibles valores predecibles, 1 o 0 (tumor benigno o tumor maligno).
El script que utilizaremos para construir y entrenar el modelo es el siguiente:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.metrics import accuracy_score import m2cgen as m2c # Define a function to load the dataset def loadDataset(fileName): data = pd.read_csv(fileName) y = np.array(data.iloc[:, 5]) x = np.array(data.iloc[:, :5]) return x, y # Load the dataset dataset_x, dataset_y = loadDataset("../../../datasets/mammographic_mass/dataset.csv") # Split the dataset into training and testing sets train_x, test_x, train_y, test_y = train_test_split(dataset_x, dataset_y, test_size=0.2, random_state=42) # Define the Logistic Regression model with the best hyperparameters model = LogisticRegression(C=0.1, max_iter=1000) # Train the model model.fit(train_x, train_y) # Make predictions on the test data pred_y = model.predict(test_x) # Evaluate the model accuracy = accuracy_score(test_y, pred_y) print('Test accuracy:', accuracy) # Generate the logistic regression model code in Java code = m2c.export_to_java(model) # Save the logistic regression model code to a Java file with open('trained_model.java', 'w') as f: f.write(code) # Print a confirmation message print('Logistic regression model code saved to trained_model.java') |
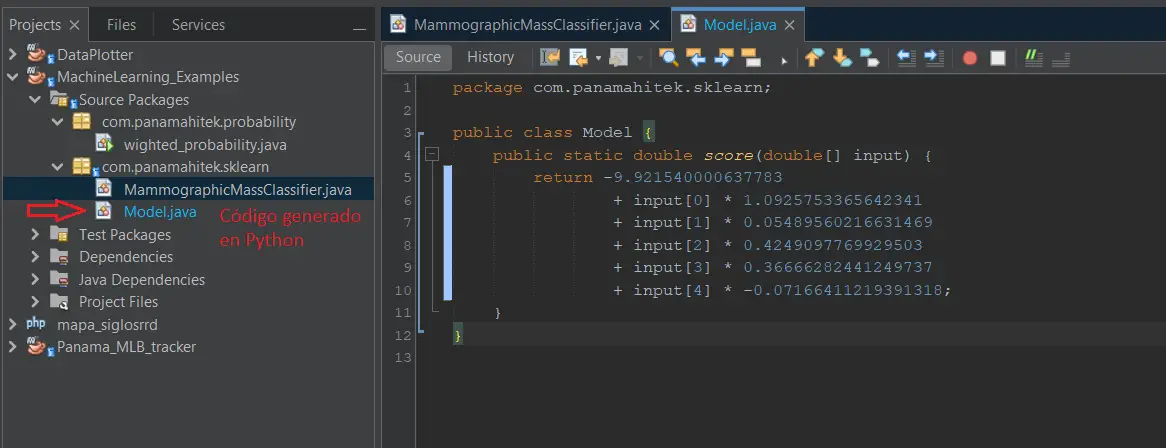
Este código está disponible en Github. El script básicamente utiliza la librería M2cgen para convertir el modelo entrenado en código ejecutable. Al ejecutar este modelo se hará hará una clasificación de datos y se creará un fichero llamado trained_model.java. Este archivo contiene el siguiente código:
|
1 2 3 4 5 6 7 8 9 10 |
public class Model { public static double score(double[] input) { return -9.921540000637783 + input[0] * 1.0925753365642341 + input[1] * 0.05489560216631469 + input[2] * 0.4249097769929503 + input[3] * 0.36666282441249737 + input[4] * -0.07166411219391318; } } |
Como vemos se trata de un código muy simple. Al tratarse de un modelo de Regreresión Logística se crea un modelo en la forma de una ecuación lineal. Cada una de los features se multiplica por un coeficiente, el cual producirá un valor que puede ser positivo o negativo.
Si el valor es mayor que cero, se considera un «1» (tumor maligno). Si el valor es menor que cero se considera un «0» (tumor benigno). Es un modelo muy simple, pero funciona.
Código en Java
Para probar este código utilizaremos el siguiente código en Java:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 |
package com.panamahitek.sklearn; import java.io.File; import java.io.FileNotFoundException; import java.util.Scanner; public class MammographicMassClassifier { public static void main(String[] args) { // Load the test dataset from CSV file String filename = "../../datasets/mammographic_mass/test.csv"; double[][] test_data = loadCsv(filename); int[] expected_results = new int[test_data.length]; for (int i = 0; i < test_data.length; i++) { expected_results[i] = (int) test_data[i][0]; } // Define the threshold for classifying examples as positive double threshold = 0.0; // Make a prediction for each sample in the test dataset int valid_results = 0; long start_time = System.currentTimeMillis(); for (int i = 0; i < test_data.length; i++) { double[] input = new double[5]; for (int j = 1; j <= input.length; j++) { input[j - 1] = test_data[i][j]; } double output = Model.score(input); int result = (output > threshold) ? 1 : 0; // Check if the predicted result matches the expected result String outcome = "Fail"; if (result == expected_results[i]) { valid_results++; outcome = " OK "; } // Print the classification results for each sample System.out.println("Nº " + (i + 1) + " | Expected result: " + expected_results[i] + " | Obtained result: " + result + " | " + outcome + " | Accuracy: " + String.format("%.2f", (double) valid_results / (i + 1) * 100) + "%"); } long end_time = System.currentTimeMillis(); double testing_time = (double) (end_time - start_time) / 1000.0; // Print the final testing results System.out.println("---------------------------"); System.out.println("Results"); System.out.println("---------------------------"); System.out.println("Testing samples: " + test_data.length); System.out.println("Testing time: " + testing_time + " s"); System.out.println("Testing accuracy: " + String.format("%.2f", (double) valid_results / test_data.length * 100) + "%"); } public static double[][] loadCsv(String filename) { // Load a CSV file into a 2D double array try { Scanner scanner = new Scanner(new File(filename)); scanner.useDelimiter(","); int rows = 0; int cols = 0; while (scanner.hasNextLine()) { rows++; String[] line = scanner.nextLine().split(","); cols = line.length; } scanner.close(); double[][] data = new double[rows][cols]; scanner = new Scanner(new File(filename)); scanner.useDelimiter(","); int row = 0; while (scanner.hasNextLine()) { String[] line = scanner.nextLine().split(","); for (int col = 0; col < cols; col++) { data[row][col] = Double.parseDouble(line[col]); } row++; } scanner.close(); return data; } catch (FileNotFoundException e) { e.printStackTrace(); return null; } } } |
Este código se encuentra disponible en nuestro repositorio de Github. El resultado de ejecutar este código en Java es el siguiente:
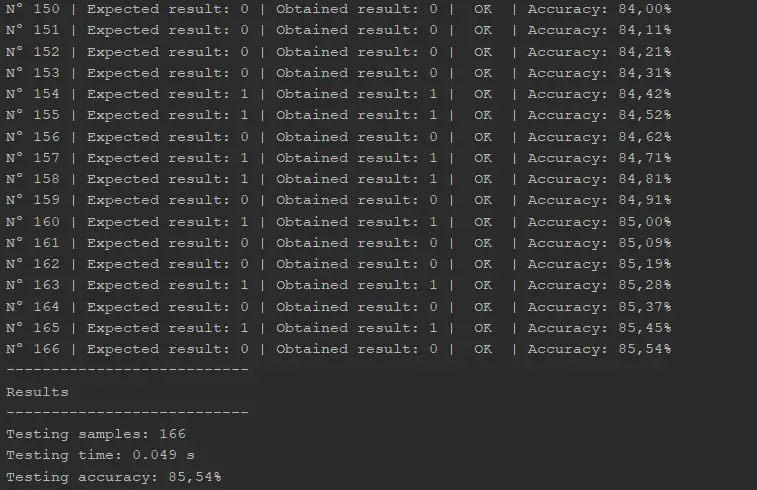
El 85.5% de eficiencia en la clasificación es consistente con el resultado obtenido en Python, el cual reportamos en nuestro post anterior.
Debo mencionar que para que este código funcione se necesita tener las dos clases en la misma carpeta. El código creado en Python debe renombrarse en Model.java. Les recomiendo que descarguen el repositorio completo y lo abran con Netbeans.
Probando con modelos más complejos
El modelo de LogisticRegression es muy simple, una ecuación lineal. Es el modelo que presentó un mejor desempeño en esta tarea específica, pero desde el punto de vista de código es muy simple.
Si cambiamos el modelo de LogisticRegression por un modelo más complejo, como Random Forest, el resultado será completamente distinto. Hice la prueba y el resultado es inmenso:
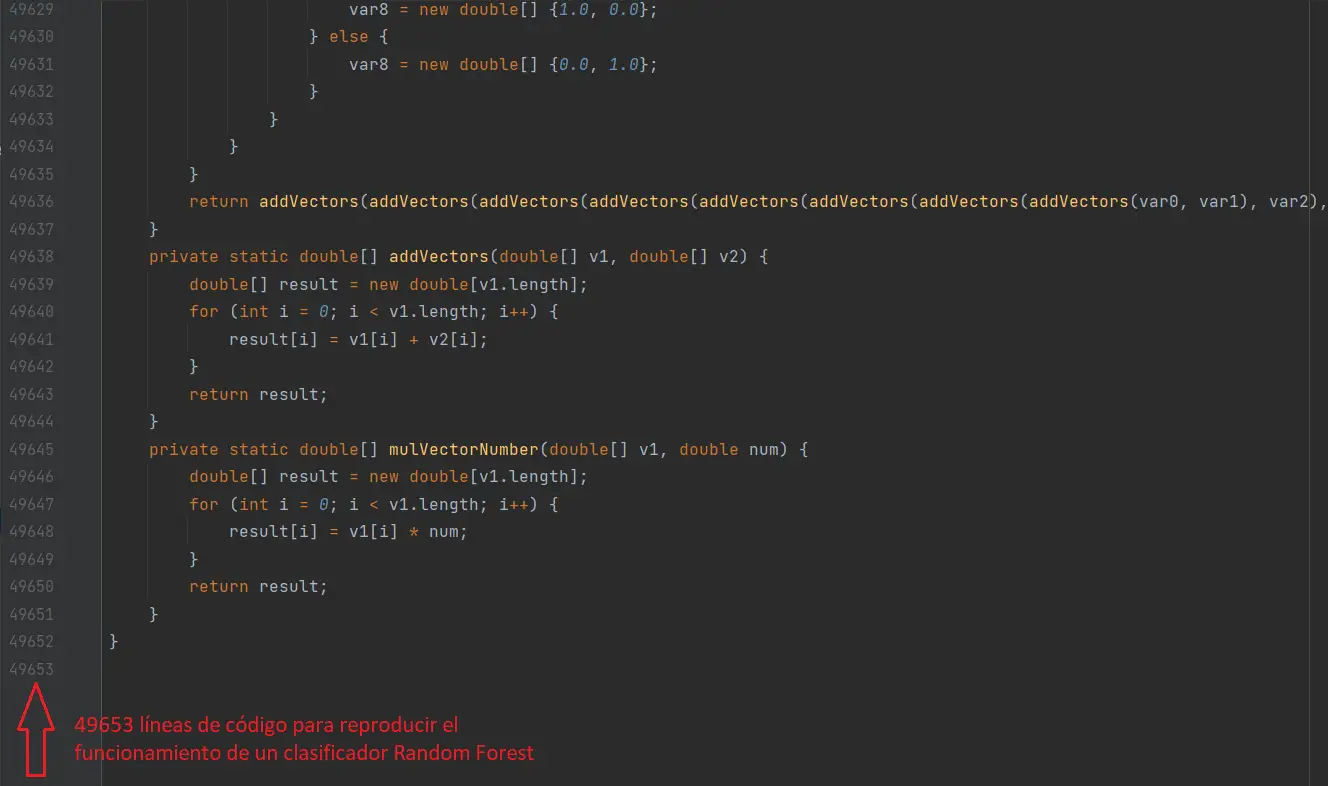
El código lo pueden encontrar aquí. En el entrenamiento en Python el resultado obtenido fue el siguiente:

Ahora intentaremos replicar este resultado en Java. Utilizaremos este código, el cual produce este resultado:
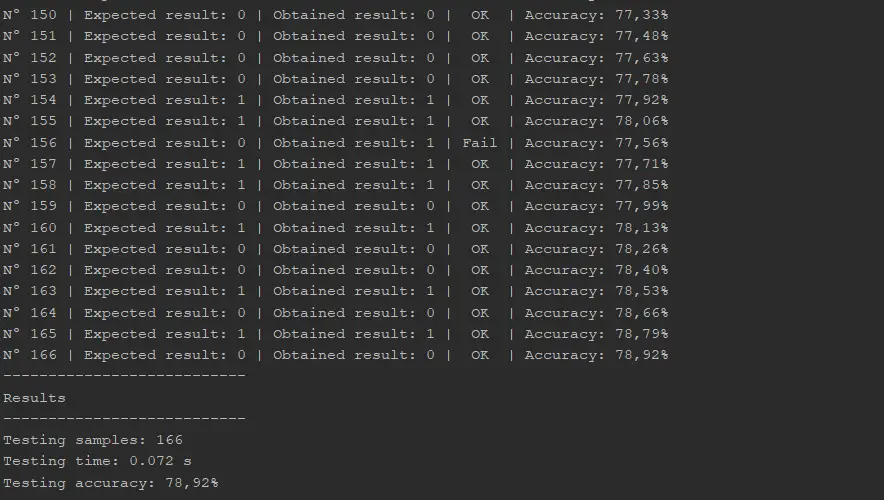
Como vemos, es el mismo resultado que en Python. Hemos logrado ejecutar exitosamente un modelo de Random Forest en Java.
Consideraciones sobre el uso de M2cgen
En algunos casos, el código generado puede ser tan grande y complejo que no se puede compilar en Java. Como ejemplo, probé un clasificador Random Forest en el conjunto de datos MNIST, como se muestra en nuestro post anterior. Sin embargo, el resultado fue una clase en Java con un peso de 150 MB y más de 1.7 millones de líneas de código.
Desafortunadamente, esta clase no pudo ser compilada para ser utilizada en Java debido a las restricciones en cuanto al tamaño de las clases en la Máquina Virtual de Java. En consecuencia, habrá ocasiones en las que no podremos utilizar el código generado, ya que será demasiado extenso para ser utilizado en una aplicación en Java. En estos casos, deberemos explorar otras opciones para poder utilizar nuestro modelo de Machine Learning en un entorno de producción en Java.
Conclusiones
En este post aprendimos cómo entrenar un modelo de Machine Learning en Python utilizando Sklearn y cómo exportarlo como código ejecutable en Java. Esta técnica nos permite aprovechar las fortalezas de ambos lenguajes de programación y utilizarlos de manera efectiva en proyectos de Machine Learning. Aunque hay limitaciones en cuanto al tamaño y complejidad del código generado, esta técnica es una excelente opción para modelos sencillos y medianamente complejos.
En casos de modelos más complejos, es importante explorar otras opciones para utilizar modelos de Machine Learning en un entorno de producción en Java.
Muchas gracias por leer este post y espero que haya sido de utilidad para ti. Si tienes alguna pregunta o comentario, no dudes en escribirlo en la sección de comentarios a continuación. Me encantaría conocer tu opinión y escuchar tus ideas sobre este tema.














