
Recientemente empecé a escribir sobre Machine Learning aquí en Panama Hitek. Ya he construído una sección especial con publicaciones sobre este tema.
Empecé escribiendo sobre un algoritmo de clasificación de imágenes de números manuscritos basado en un Support Vector Machine. Lo que haré en este post será repetir el procedimiento de ese post, pero utilizando un clasificador Random Forest disponible en la librería Sklearn en Python.
El algoritmo Random Forest es uno de los más populares en cuanto a Machine Learning en la actualidad, o al menos así lo creo yo. Siento que últimamente una gran parte de los papers que he estado leyendo en cuanto a Machine Learning utilizan el algoritmo Random Forest, el cual normalmente se destaca con respecto a otros. Al menos en las tareas en los cuales he visto que lo han estado utilizando.
Una vez más, este será un post meramente técnico sin entrar mucho en la teoría de como funciona el algoritmo de clasificación Random Forest. Ese es un tema que debería desarrollar en un post dedicado a tal propósito. Por ahora lo que haré será compartir un script con un clasificador Random Forest, utilizarlo con el dataset MNIST y evaluar el performance del algoritmo con respecto al Support Vector Machine de mi post anterior.
El siguiente script está disponible en nuestro repositorio en Github:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 |
import pandas as pd import numpy as np import time as time from sklearn import svm from sklearn.ensemble import RandomForestClassifier trainingSamples = 50000 # Self explanatory testingSamples = 10000 """ Here I set the global variables, which will be used to test the computing time for both training and testing """ startTrainingTime = 0 endTrainingTime = 0 trainingTime = 0 startTestingTime = 0 endTestingTime = 0 testingTime = 0 def loadDataset(fileName, samples): # A function for loading the data from a dataset x = [] # Array for data inputs y = [] # Array for labels (expected outputs) train_data = pd.read_csv(fileName) # Data has to be stored in a CSV file, separated by commas y = np.array(train_data.iloc[0:samples, 0]) # Labels column x = np.array(train_data.iloc[0:samples, 1:]) / 255 # Division by 255 is used for data normalization return x, y def main(): train_x, train_y = loadDataset("../datasets/mnist/mnist_train.csv", trainingSamples) # Loading training data test_x, test_y = loadDataset("../datasets/mnist/mnist_test.csv", testingSamples) # Loading testing data clf = RandomForestClassifier() # Classifier object startTrainingTime = time.time() clf.fit(train_x, train_y) # Training of a model by fitting training data to object endTrainingTime = time.time() trainingTime = endTrainingTime - startTrainingTime # Training time calculation validResults = 0 startTestingTime = time.time() for i in range(len(test_y)): # A for loop to evaluate result vs expected results expectedResult = int(test_y[int(i)]) # Load expected result from testing dataset result = int( clf.predict(test_x[int(i)].reshape(1, len(test_x[int(i)])))) # Calculate a result using trained model outcome = "Fail" if result == expectedResult: validResults = validResults + 1 # Counting valid results outcome = " OK " print("Nº ", i + 1, " | Expected result: ", expectedResult, " | Obtained result: ", result, " | ", outcome, " | Accuracy: ", round((validResults / (i + 1)) * 100, 2), "%") # Printing the results for each label in testing dataset endTestingTime = time.time() testingTime = endTestingTime - startTestingTime # Calculation of testing time print("-------------------------------") print("Results") print("-------------------------------") print("Training samples: ", trainingSamples) print("Training time: ", round(trainingTime, 2), " s") print("Testing samples: ", testingSamples) print("Testing time: ", round(testingTime, 2), " s") print("Testing accuracy: ", round((validResults / testingSamples) * 100, 2), "%") if __name__ == "__main__": main() |
El resultado de la ejecución de este script es el siguiente:
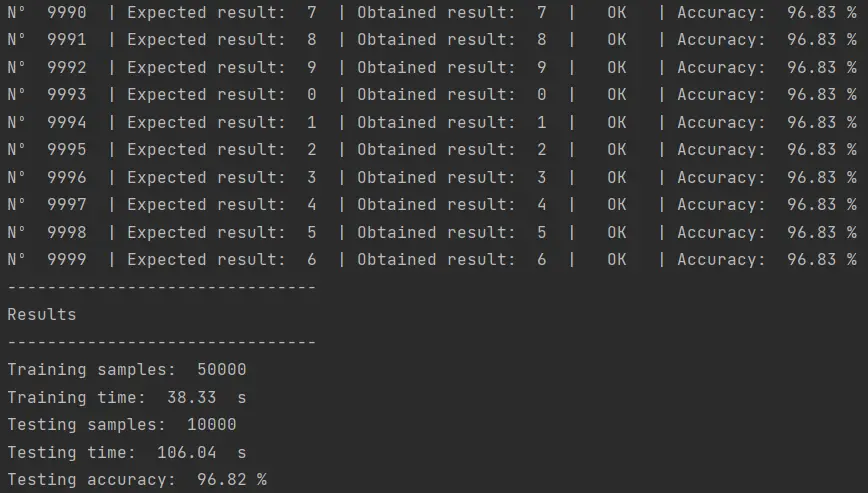
Aunque la eficiencia de este algoritmo es menor que la que obtuvimos con el Support Vector Machine (97.84%), el tiempo de entrenamiento es mucho menor (38 segundos vs. 173 segundos). El tiempo de pruebas es de 106 segundos, más o menos el mismo tiempo que el algoritmo SVM con un kernel RBF (104 segundos), que fue el algoritmo que presentó el mejor performance en el post anterior.
Esta es una de las razones por las cuales el algoritmo Random Forest es tan popular. Presenta un buen performance en tareas de clasificación de datasets con grandes cantidades de datos y el tiempo de ejecución es bastante rápido en comparación a otros algoritmos de clasificación.
Optimización de parámetros
En el algoritmo de clasificación Random Forest es posible configurar distintos parámetros que pueden mejorar el performance del algoritmo a cambio de un mayor tiempo de entrenamiento y clasificación. En el caso de la librería Sklearn, estos son los parámetros del clasificador en cuestión:
class sklearn.ensemble.RandomForestClassifier(n_estimators=100, *, criterion=‘gini’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=‘sqrt’, max_leaf_nodes=None, min_impurity_decrease=0.0, bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, class_weight=None, ccp_alpha=0.0, max_samples=None)
Podemos probar modificando todos esos valores para obtener mejores resultados. Por ejemplo, al utilizar 200 estimadores, en vez de los 100 que se utilizan por default, el resultado es el siguiente:
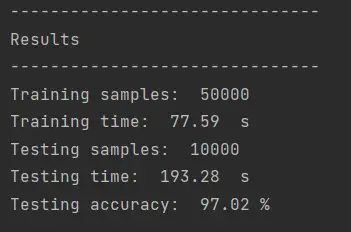
Utilizando 300 estimadores, este es el resultado:
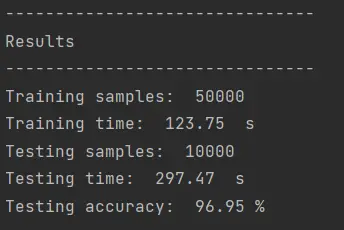
Vemos que se redujo el performance y aumentaron los tiempos de prueba y de entrenamiento, por lo cual no podemos decir que con solo aumentar la cantidad de estimadores es igual a mejorar el rendimiento.
Se pueden probar distintas combinaciones de parámetros para este algoritmo, pero ese es un tema que abordaré en detalle en un post dedicado a ello. Por lo pronto concluimos que el algoritmo Random Forest es bastante eficiente en cuanto a precisión y tiempo de procesamiento.
Probando el clasificador Random Forest con mi propia escritura
Hace unos días escribí un post en el que probé el clasificador basado en el Support Vector Machine con mis propios números manuscritos. En esta sección probaré el clasificador Random Forest con mis propios números. El script es el siguiente:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
import pandas as pd import numpy as np import time as time from sklearn import svm from sklearn.ensemble import RandomForestClassifier trainingSamples = 50000 # Self explanatory testingSamples = 10 """ Here I set the global variables, which will be used to test the computing time for both training and testing """ startTrainingTime = 0 endTrainingTime = 0 trainingTime = 0 startTestingTime = 0 endTestingTime = 0 testingTime = 0 def loadDataset(fileName, samples): # A function for loading the data from a dataset x = [] # Array for data inputs y = [] # Array for labels (expected outputs) train_data = pd.read_csv(fileName, header=None) # Data has to be stored in a CSV file, separated by commas y = np.array(train_data.iloc[0:samples, 0]) # Labels column x = np.array(train_data.iloc[0:samples, 1:]) / 255 # Division by 255 is used for data normalization return x, y def main(): train_x, train_y = loadDataset("../datasets/mnist/mnist_train.csv", trainingSamples) # Loading training data test_x, test_y = loadDataset("../datasets/custom/custom_mnist.csv", testingSamples) # Loading testing data clf = RandomForestClassifier() # Classifier object startTrainingTime = time.time() clf.fit(train_x, train_y) # Training of a model by fitting training data to object endTrainingTime = time.time() trainingTime = endTrainingTime - startTrainingTime # Training time calculation validResults = 0 startTestingTime = time.time() for i in range(len(test_y)): # A for loop to evaluate result vs expected results expectedResult = int(test_y[int(i)]) # Load expected result from testing dataset result = int(clf.predict(test_x[int(i)].reshape(1, len(test_x[int(i)])))) # Calculate a result outcome = "Fail" if result == expectedResult: validResults = validResults + 1 # Counting valid results outcome = " OK " print("Nº ", i + 1, " | Expected result: ", expectedResult, " | Obtained result: ", result, " | ", outcome, " | Accuracy: ", round((validResults / (i + 1)) * 100, 2), "%") # Printing the results for each label in testing dataset endTestingTime = time.time() testingTime = endTestingTime - startTestingTime # Calculation of testing time print("-------------------------------") print("Results") print("-------------------------------") print("Training samples: ", trainingSamples) print("Training time: ", round(trainingTime, 2), " s") print("Testing samples: ", testingSamples) print("Testing time: ", round(testingTime, 2), " s") print("Testing accuracy: ", round((validResults / testingSamples) * 100, 2), "%") if __name__ == "__main__": main() |
El resultado obtenido es:
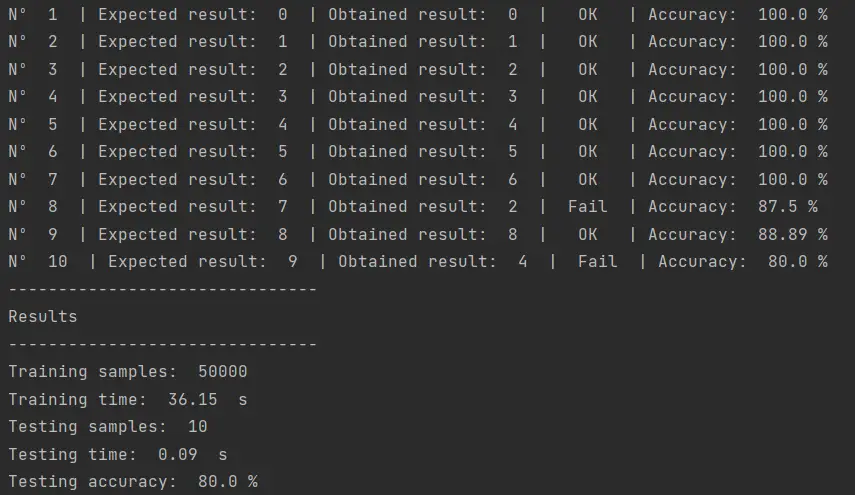
El mismo inconveniente que con el Support Vector Machine, la imposibilidad de reconocer el 7 y el 9. Los resultados no mejoraron utilizando más estimadores, ni tampoco con el procesamiento que describimos en el post en el que probamos el SVM.
Por lo pronto, esto es todo lo que quiero compartir sobre el clasificador Random Forest. Logramos un procesamiento más rápido, con un performance comparable al del SVM. Seguimos teniendo problemas con la clasificación de mis números manuscritos y nos queda pendiente explicar en detalle en qué consiste el algoritmo Random Forest desde el punto de vista matemático y la explicación de cómo escoger los mejores parámetros para el clasificador a través de un procedimiento de Cross Validation.
Espero que esta información les sea útil. Cualquier duda o comentario me lo pueden hacer llegar a través de la caja de comentarios.

")










")